

はじめに
エクサでは、社内のエンジニアが持っている技術情報や経験を共有・閲覧できるサービス「Knowledge」を運用しています。
こちらは同名のOSSをベースとしており、エクサの社員が使いやすいように継続的なアップデートをしています。
Knowledgeの詳細についてはこちらの記事をご参照ください。
Knowledgeは社内での技術情報の共有・活用の活性化を目的として2018年から運用していますが、やはり道のりは険しく、苦戦を強いられています。
似たようなサービスを運用されている方なら共感していただけるかもしれませんが、このようなサービスを社内で運用する場合、共有・活用の両方の側面において以下のような課題があります。
-
共有(技術情報などの投稿)
- 同じ人しか記事を投稿しない
- 業務を遂行しながらだと記事を書く時間が取れない
- 「体系立ててまとめる」という作業が大変
-
活用(投稿された情報の業務への活用)
- せっかく投稿された情報があまり活用されない
- 調べものをするなら、Webで検索した方が早いうえに情報量も桁違いに多い
- せっかく投稿された情報があまり活用されない
なかなか解決の難しい課題ではありますが、「AIを活用すれば解決できるのでは?」と考え、2025年1月以降、エンジニア歴10年目でAIの知識がゼロだった筆者が1人でKnowledgeに生成AIを活用して多数の機能追加・改善を行いました。本稿ではこの取組についてご紹介します。
AIの知識ゼロから始めてもこの程度は実装できましたので、皆さんも臆せずどんどんAI使っていきましょう!
なお、KnowledgeサービスはAWS上で動かしています。
生成AIサービスとしてAmazon Bedrockというサービスがあり、これを活用しています。
BedrockにはAmazonが開発したモデルだけでなくAuthropic社のClaudeなど、多数のLLM(Large Language Models:大規模言語モデル)がデプロイされており、開発者はWeb API経由で手軽に利用できます。
課金体系は、LLMへの入出力トークン数(≒ 入出力文字数)に応じた従量課金制です。コスト効率は良いものの、大量の情報処理には高額な料金が発生する可能性があるため、開発時に注意が必要です。
実装したAI機能
Knowledgeに実装したAI機能は以下の通りです。
- 1.
-
OpenSearch検索
- 2.
-
AIチャットボット
- 3.
-
自動テンプレート作成・AIレビュー機能
- 4.
-
AIエージェント
- 5.
-
Google検索時にKnowledge検索も同時に行うChrome拡張機能
まず「活用」支援機能として、自然言語でKnowledgeに関する質問ができるチャットボットのリリースを目指しました。
その準備段階としてAWS OpenSearchをデータソースとした検索機能を開発し、その後チャットボットの開発を行いました。
当時は知識も経験もありませんでしたが、エクサには社内情報に回答するチャットボットたまちゃんが既に存在したため、その技術情報版をイメージして開発に着手しました。
(たまちゃんの開発知見もKnowledgeに投稿されていたので、活用させていただきました。)
その後、今度は「共有」支援機能として自動テンプレート・AIレビュー機能を開発しました。
さらにAIチャットボット開発で得た知見をもとに、当時のトレンドであったエージェント型AIにも対応しました。
最後にAIチャットボット開発のリソースを再利用して、自然なユーザ体験でKnowledge検索も同時に行えるようなChrome拡張機能を開発しました。
その後もLLMのモデルアップデートなど、継続的なアップデートを実施中です。
機能解説
1. OpenSearch検索
Knowledgeにも検索機能は実装されていますが、検索目的に合っていない記事がヒットしてしまうことも多く、検索機能としてはあまり利用されていませんでした。そこで、より検索目的に合致した記事を検索しやすくなるようにAWS OpenSearchを使った検索機能を実装しました。
ユーザ視点からみると単なる検索機能ですが、次に紹介するAIチャットボットでは重要な役割を担っているので、ここで紹介いたします。
こちらの検索機能の特徴としては、ドキュメントからキーワードとして指定されたものが含まれているものを検索する「テキスト検索(全文検索)」に加えて「ベクトル検索」も実施する、「ハイブリッド検索」を実装しています。
ベクトル検索とは、検索対象のドキュメントと入力された検索キーワードをAIを用いてそれぞれベクトルとしてマッピングし、最も類似度の高いN件(近傍N件)を返す検索アルゴリズムです。(図1参照)
ベクトル値の距離を指標とするため、検索キーワードと意味合いが近しいものが検索できる、という特徴があります。
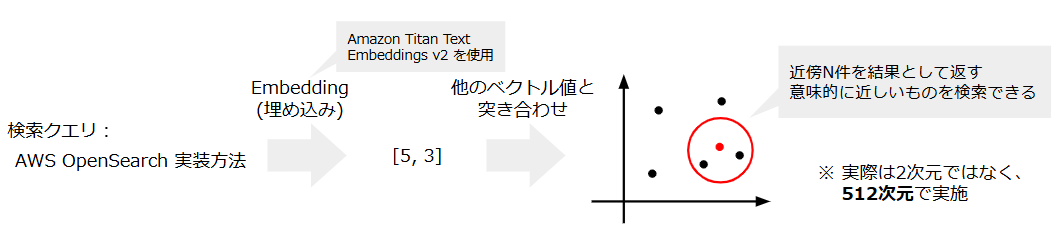
図1. ベクトル検索
「ベクトル検索の方が"テキストの意味合い"で検索できるため優れている」というわけではなく、テキスト検索、ベクトル検索それぞれにメリット・デメリットが存在します。(表1)
| メリット | デメリット | |
|---|---|---|
| テキスト検索 | 検索キーワードにマッチングしたものを返すため、検索目的が明らかである場合に有効 | 検索目的が曖昧であり、キーワードが抽象的である場合はうまく検索に引っかからない |
| ベクトル検索 | キーワードが抽象的でも、意味的に近しいものを検索できる | 検索目的が明確な場合、検索ノイズにより本当に検索したかったドキュメントが埋もれる可能性がある |
このように、両方の検索アルゴリズムで一長一短であるため、両方の検索を行いその検索スコアを合算することにより、検索精度の向上を図っています。これが「ハイブリッド検索」です。
データ更新
KnowledgeはデータベースとしてAmazon RDSを使っており、投稿された記事情報などもここに保存されているので、OpenSearchに記事情報を同期する必要があります。
今回はこのための手法として「AWS Glue(※)を使って毎日深夜に新規・更新データをOpenSearchに同期する」という手法を選択しました。(図2参照)
日を跨がないと投稿された記事がOpenSearch検索では検索できない、という問題点はありますが、1日に投稿される記事は平均すると10件以下程度であり検索される頻度も現状多くはないので、この問題点は許容できると判断しました。
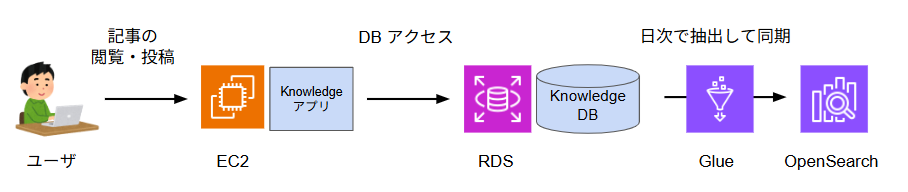
図2. Glueでのデータ抽出
リアルタイム性を求める場合はAWS Data Migration Serviceなどの利用が選択肢となりますが、コストも高く1日の投稿数・検索回数からみると費用対効果に見合っていないので見送りました。
後述しますが、結果的に今回の手法で運用コストも安価で済みましたし、必要十分だったと思っています。
※
AWS Glueとは、AWSマネージドのETL(Extract/Transform/Load)サービスです。
RDSなどのデータソースからデータを抽出・加工し、別のストレージに書き出すETLジョブの作成・実行が容易に可能です。
2. AIチャットボット
こちらの機能はいわゆるRAG(Retrieval Augmented Generation)アプリケーションです。
RAGとは、図3のように外部から取得したリソースをLLMへのプロンプトに含めることで通常LLMが知り得ないことを回答させる手法です。
今回のような社内ドキュメントや、LLMがまだ学習していない最新情報を使って回答を生成させたい場合に有効です。
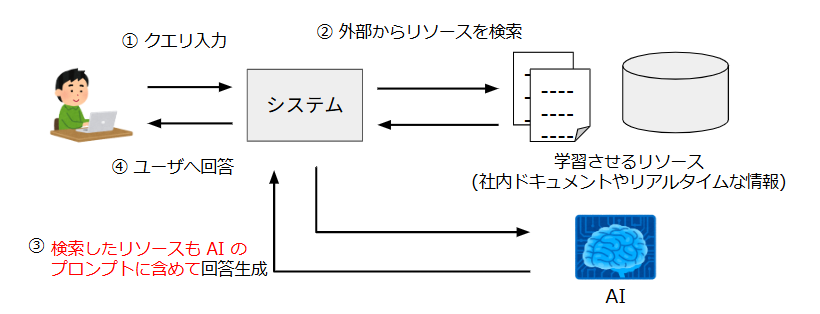
図3. RAGの処理フロー図
②の検索プロセスにおいて、データソースとして検索に特化した検索エンジンを使うことが非常に重要です。
RDBやオブジェクトストレージに保管した場合よりも多様な条件で検索クエリを書くことができ、ベクトル検索に代表されるセマンティック検索も可能となるためです。また、キーワードに対する合致度順でランク付けされた状態で検索結果を返せるので、これを考慮することで③の回答生成プロセスでもより精度の高い回答生成が可能となります。
そのために、まずはOpenSearchを使った検索ができるようにしました。
機能の解説に戻ると、自然言語で質問を入力するとKnowledgeから情報を検索し、それをもとにAIが回答を生成します。
図4の例では、ここ3ヶ月で受講された社外研修と、その感想を列挙するように依頼しています。ChatGPTやGeminiなどの全世界に公開されているチャット型AIだとエクサの内部情報まで分からないので当然回答できませんが、Knowledgeに投稿された研修受講実績記事を検索してLLMに渡しているため、回答が可能です。
(掲載にあたり、受講した研修名と受講者名は黒塗りしています。)

図4. AIチャットボット使用例
AIチャットボットのアーキテクチャとしては図5のとおりです。
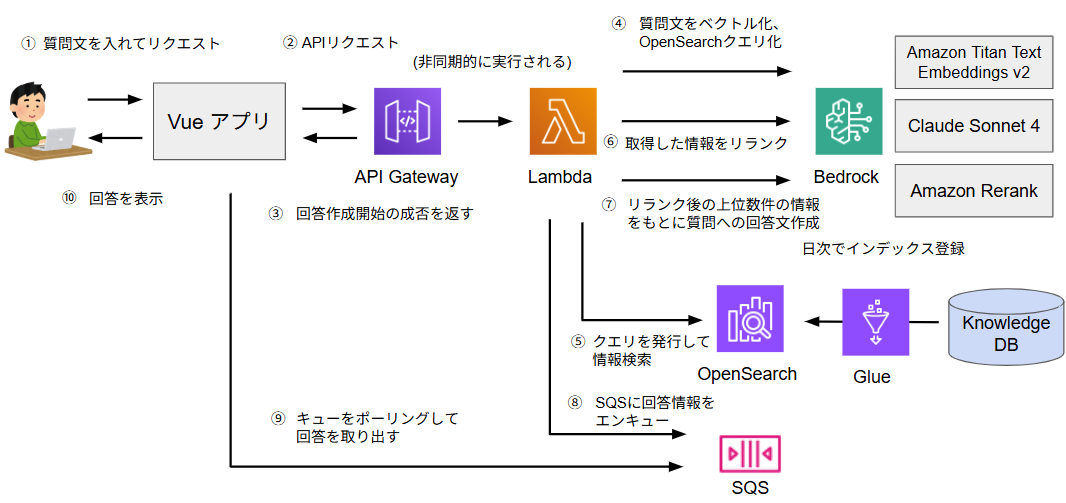
図5. AIチャットボットのアーキテクチャ
④の質問文のOpenSearchクエリ化、⑦の回答生成でClaude Sonnet 4に対してリクエストを行っていますが、この時のプロンプトでは以下の点で工夫しています。
質問文のOpenSearchクエリ化
-
クエリのサンプルもプロンプトに含めて「これを参考にして作れ」と指示
- 稀に誤ったフォーマットのクエリを返すことがあるが、適切なサンプルを提示することでこの問題は解消
-
質問文を解釈して、それに沿って適切なフィルタリングやソートするクエリを作成するように指示
- 例:
- 「ここ◯ヶ月以内に投稿された...」という質問文の場合は投稿日時が今日から◯ヶ月以内のものをフィルタリング
- 「人気の記事を教えて」という質問文の場合は記事の「イイね」数でソート
- 例:
-
通常は20件の記事情報を取得するようにしているが、記事の量が重要な質問だと判断した場合は記事タイトルのみを上限50件で取得するクエリを作成するように指示
- 「◯◯に関する記事をできるだけ多く探して」「◯年間で受講された研修一覧を教えて(20件では足りないと想定されるもの)」など
回答生成
-
自分が何者なのか、何ができるのかをプロンプトの冒頭で記載
- 使い方が分からないユーザに「あなたは何ができますか?」のような質問が来た場合も使い方のチュートリアルを返せる
-
"必ず"文章が完結した形でまとめるように指示
- 出力トークン数の制限によって文章が途切れてしまうことがあるため、その対策
- "必ず"を強調しないと完結しない文章で生成される場合もあり
-
検索で取得した記事情報リストとして投稿者情報も一緒に渡しているが、名前が多く挙がっている人がいれば「より詳しく知りたい場合、◯◯さんに聞いてみると良いかもしれません」と提案するように指示
- ユーザの次のアクションを明確にする
- 社内のコミュニケーション活性化の狙いもあり
また、特徴として「リランク」という手法を使い回答生成の精度を向上させています。
これは、OpenSearchはクエリへのマッチ度順で検索結果が返されますが、ここからさらにリランク用のモデル(Amazon Rerank)を使い、ユーザから入力された質問文とのマッチ度合いで並び替えを行う手法です。
図5のフローを見ていただくと分かるとおり、ユーザから入力された質問文そのものでOpenSearch上の情報を検索しているわけではなく、質問文をベクトル化やOpenSearchクエリ化して検索しています。
変換を行っている過程で質問文の意味的背景などが抜け落ちてしまっている場合もあり、「本当に質問文の意図に合致するもの」が検索できている保証はありません。そのため、リランクによって検索結果の並べ替えを行っています。
Knowledgeでは、⑤の検索では20件取得し、⑥のリランクで上位5件に間引いて⑦の回答生成プロセスに渡しています。精度評価は十分にはできていませんが、これで体感ではかなり精度の良い回答が可能となりました。
記事の量が重要な質問の場合は⑤で21件以上取得されるので、その時はリランクは行っていません。
なお、この一連の回答生成処理はAmazon SQSというキューイングサービスを使って非同期処理にしています。
これは回答生成処理が複雑な都合上、30秒以上かかる場合があるためです。API Gatewayは30秒のタイムアウト制限があるため、同期処理だと処理できずにエラーとして返ってくることがあります。
回答生成中にユーザがページをリロードしたりページから一時的に離れたりしても、確実に回答を返せるというメリットもあります。
3. 自動テンプレート作成・AIレビュー機能
少しでも手軽に投稿してもらえるよう、記事を作成する際の支援機能を2種類実装いたしました。自動テンプレート作成機能とAIレビュー機能です。
「自動テンプレート作成機能」はタイトルから記事構成をAIが自動作成します。(図6参照)
「AIレビュー機能」は編集中の記事に対し、AIによるレビューを可能にします。(図7参照)
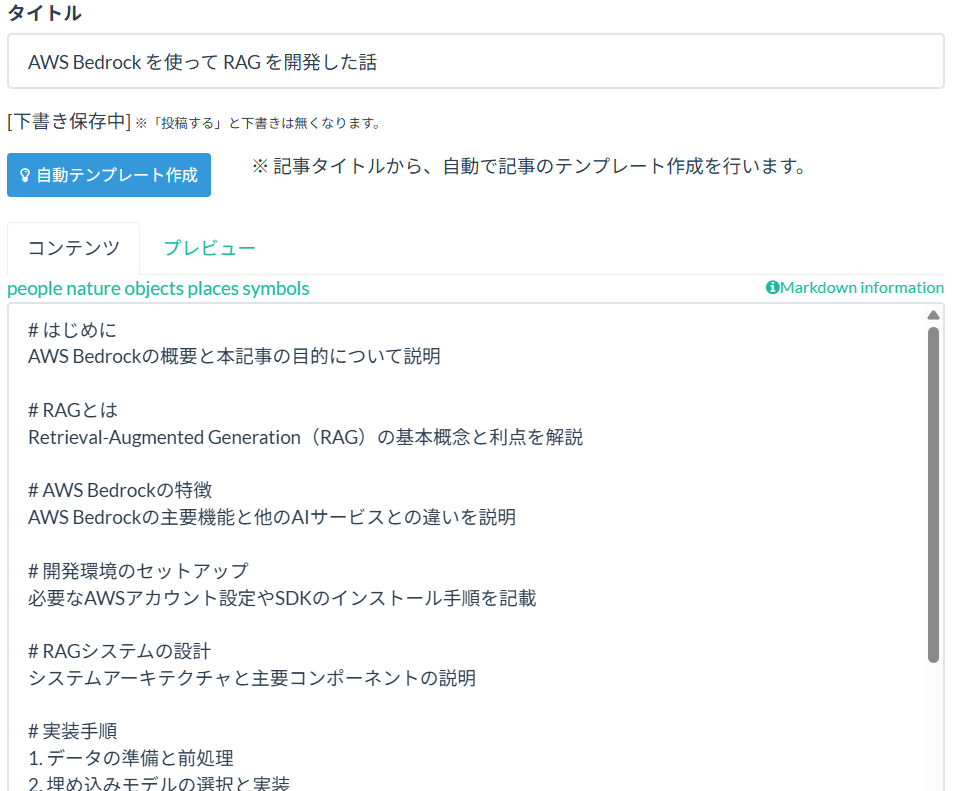
図6. 自動テンプレート作成機能
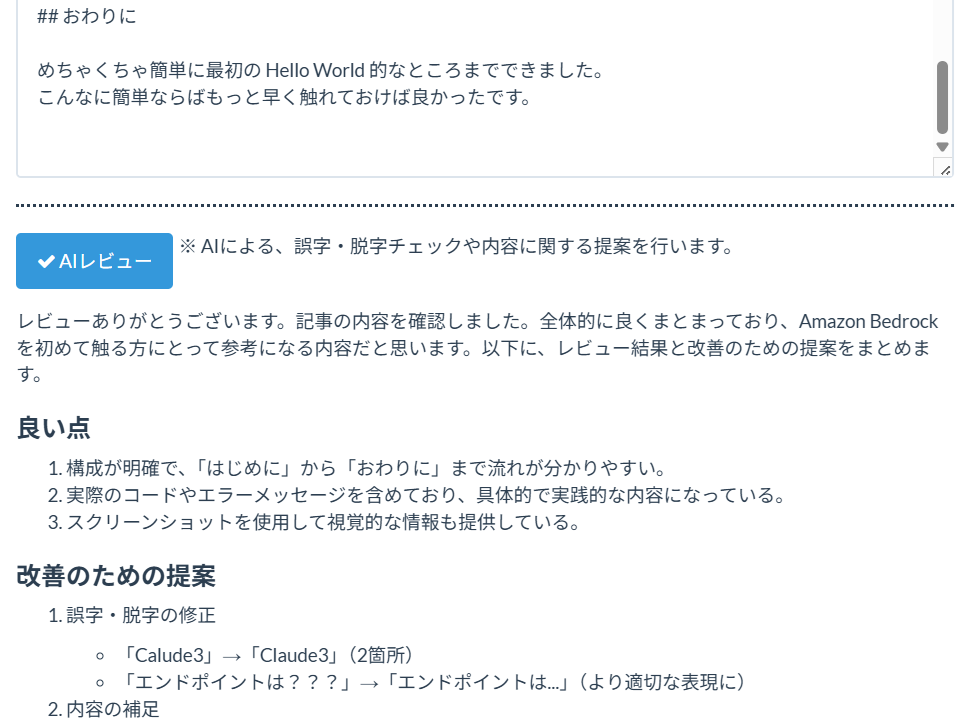
図7. AIレビュー機能
「自動テンプレート作成機能」は文章構成を考える手間を軽減します。出力されたものをそのまま使わずとも、これをたたき台にして編集して使うこともできます。
「はじめに」で述べた通り、「人が読んだ時に理解しやすいように体系立ててまとめる」という作業が1つのハードルとなりますが、これで少しは記事を作りやすくなると思います。
また記事完成後、投稿する前に客観的な意見がほしい時はままあります。
「下手なものを公開して批判されたらどうしよう」など思ってしまい、せっかく書いたもののなかなか投稿できずにいる、というような経験をしたことがある方は、こういった情報共有サービスに限らず多いんじゃないでしょうか。実際には、少なくともエクサにはそんな否定的な意見を言う人はいないんですけどね。
こういった時に他人にレビューをお願いするのも難しい場合が多いです。
「AIレビュー機能」はこのような場合に気軽に客観的な意見がもらえる機能として実装しました。
どちらも処理フローとしては同じなので、本稿では「AIレビュー機能」の技術的仕組みについて詳しく説明いたします。
仕組みとしてはAmazon API Gateway + AWS Lambda + Amazon Bedrockでレビュー用のAPIを開発しており、記事作成画面からこのAPIを呼び出し、結果を画面上に描画することで実現しています。(図8参照)
自動テンプレート機能の場合、同様に記事タイトルをリクエストとして渡し、記事構成のテンプレートをレスポンスとして受け取っています。
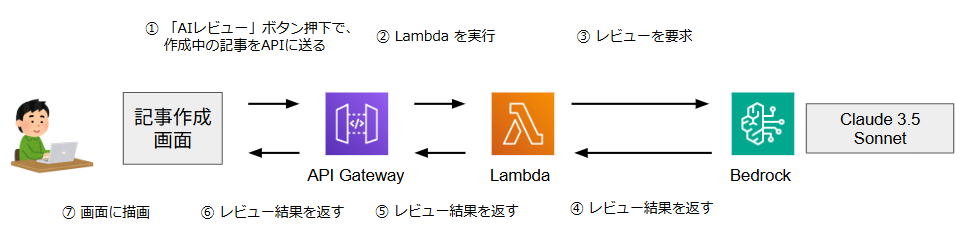
図8. AIレビュー機能の処理フロー
Bedrockにリクエストとして渡すプロンプトでは、以下の点で工夫しています。
-
レビューを依頼するうえでAIが毎回初見のリアクションをしないよう、過去のやり取りを考慮するように実装
- この対応がない場合、指摘を修正して再レビューを依頼すると、次々と新たな点を指摘されるため、ユーザ的にはいつまで経っても気持ちよく投稿ができない
-
指摘した部分が修正されていた場合はちゃんと褒めるように指示
- これもユーザに良い気分になってもらうように
-
本システムでは技術記事、研修参加報告記事、新人研修での新人の日報、などいくつかの記事カテゴリを指定できるが、記事カテゴリに合ったレビューをするように指示
- 特に新人日報記事の場合、ビジネス文書としての体裁が整っているかどうかもチェック項目を列挙して確認するようにしている
「記事作成画面」で記事作成後、そのままその画面上に配置されたボタンをワンクリックで使える、という機能アクセスへの導線の良さもあると思いますが、「AI レビュー機能」は今回紹介する機能の中では一番利用されています。
4. AIエージェント
AIエージェントはAIチャットボットをさらに発展させた機能です。現状そこまで作り込めてはいないのですが、チャット型AIとエージェント型AIの違いを体験してもらえるように公開しています。
最近では、ただ指示されたことを実行するだけにとどまらず自律的に考えてアクションを起こすようなエージェント型AIが注目されているので、今後この機能はさらにブラッシュアップしていきたいと思っています。
チャット型AIは、「最終的に達成したいこと・知りたいこと」があったとしてそのために必要なアクションは当然ですが人間がブレイクダウンして、各アクションにて人間がAIに質問することでこれを手助けします。
一方、エージェント型AIは「最終的に達成したいこと・知りたいこと」をインプットとして渡すだけで、それに対して何のアクションが必要かのブレイクダウンすらAIが実施してくれる、という違いがあります。
今回はAIエージェントとして、Knowledgeの社内情報とWebの一般情報をどのように検索するかを自律的に考えて回答を生成する機能を開発しました。
この機能のアーキテクチャは図9のようになります。
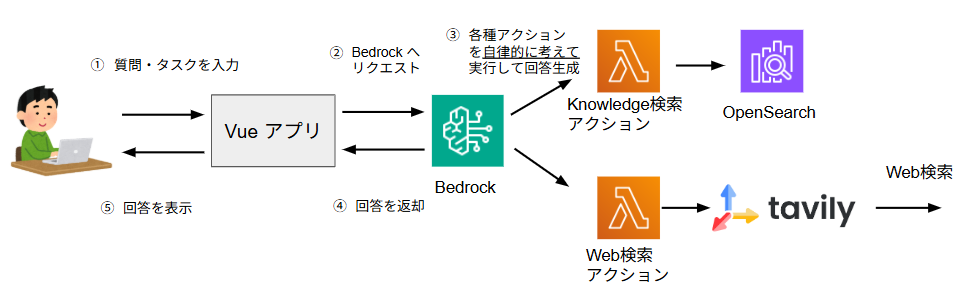
図9. AIエージェントのアーキテクチャ
AIエージェントは、以下の5つのステップに基づいて行動するようにプロンプトで指示しています。
- 1.
-
タスク完了のための計画立案
- 2.
-
検索キーワードの考察
- 3.
-
検索の実行(Knowledge検索、Web検索の両方)
- 4.
-
追加調査の必要性判断
- 5.
-
回答の生成
こちらの機能の場合、ステップ3でTavilyという検索エンジンを用いてWeb検索も行っており、Knowledge上の情報のみを使って回答するAIチャットボットよりも、幅広い知識を活用した回答が可能となります。
検索で情報を集めた後、ステップ4で回答に必要な情報が充足しているかの判断を行い、足りていないと判断した場合はステップ2に戻ってさらに検索を行います。
このように、単純に順番通りに実行するだけでなく、AIが自律的に考えてアクションを起こします。
この程度であれば、Bedrockのエージェント機能を用いることで簡単に実装できました。
エージェントに対する命令をプロンプトとして書いておけば、Bedrockエージェントが「エージェント化」に関わる一連の処理を自動で実行してくれます。
入力されたプロンプトを実行可能なステップに分割して順序立てて実行する、LLMから返ってきたレスポンスを次のステップのインプットにする、など。
5. Google検索時にKnowledge検索も同時に行うChrome拡張機能
最後に、「情報の活用」を支援する仕組みとしてこれまでとは別のアプローチで開発したものを紹介いたします。
Knowledgeではあまり検索機能が使われていません。
「はじめに」でも述べたとおり、Knowledgeを検索するよりもGoogleでWeb検索を行う方が情報の量が桁違いに多いためです。
また、「操作の慣れ」も起因しています。現代人は基本的に「何か分からないことがあった場合はGoogleで検索する(ググる)」という操作が習慣として染み付いており、わざわざKnowledgeを検索する、という操作はされないでしょう。
Knowledgeには社員の皆さんに投稿していただいた、技術の応用・活用例やエクサのネットワーク環境特有の問題の解決方法など、Web検索では得られない素晴らしい情報が集まっていますが、これではせっかくの情報が活用されず非常にもったいない状況です。
そこで、株式会社サーバーワークス様のこちらのブログ記事を参考にさせていただき、Google検索時にKnowledgeの情報も検索して検索結果に埋め込むGoogle Chromeの拡張機能を開発して配布しています。
これで、自然なユーザ体験でKnowledge上の情報も検索できるようになりました。
図10は、拡張機能をインストールした状態で「opensearch」とGoogle検索してみた時の検索画面になります。
右側のエリアにKnowledgeを検索した結果も表示しています。
なお、仕組みとしてはKnowledgeをWebに公開しているわけではなく、拡張機能を介してGoogle検索時に同じキーワードでKnowledge検索も同時に行い、その結果をGoogle検索結果のHTMLに埋め込んでいます。
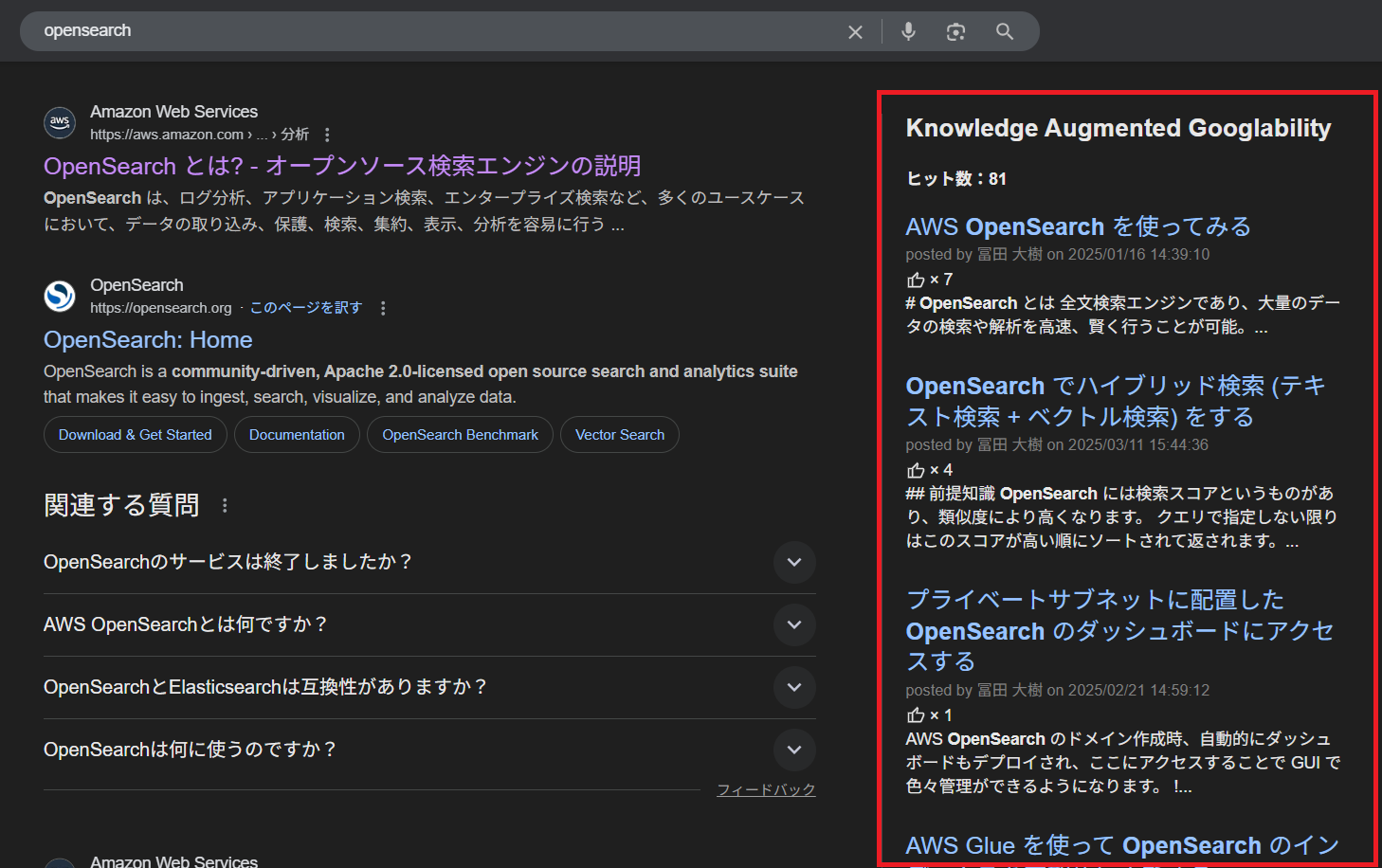
図10. 拡張機能の使用例
コスト
学習・開発コスト
「はじめに」でも述べていますが、筆者はこの開発以前のAI知識はゼロでした。
そんな状態から1人でAI領域を学習するところから取り組み、6つの機能(OpenSearch検索、AIチャットボット、自動テンプレート、AIレビュー、AIエージェント、Chrome拡張機能)を開発するまでに要した工数は約4人月です。
運用コスト
本システムはAWS上で動かしているので、運用コストは気になるところかと思います。
2025年1月〜6月までで実績としてかかったAWSの運用コストを表2にまとめました。
なお、ここに挙げているのはあくまでもAI機能のコストのみです。実際にはシステム運用の基盤として利用しているEC2やRDSなどのコストもかかっています。
社内システムなので1日に多くても記事投稿は10件に満たない程度ですが、この規模感のシステムとしてはこれくらいのコスト感になります。
| 1月 | 2月 | 3月 | 4月 | 5月 | 6月 | |
|---|---|---|---|---|---|---|
| OpenSearch | 43.48 | 75.55 | 81.07 | 78.50 | 81.07 | 78.50 |
| Bedrock | 0.26 | 4.59 | 16.40 | 44.21 | 4.66 | 9.94 |
| Glue | 0.00 | 9.53 | 1.34 | 0.79 | 0.78 | 0.78 |
| Lambda | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| API Gateway | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| SQS | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
OpenSearchはEC2などと同じようにインスタンス起動時間分のコストがかかるので、比較的高額です。インスタンスタイプは安価なr7g.medium.searchで冗長化もせずシングルインスタンスで動かしているので最小構成に近いのですが、これくらいの費用は発生します。
今回はオンデマンドインスタンスを作成しました。
OpenSearchにはOpenSearch Serverlessというサーバレスサービスもあり、こちらはアクセス数に応じた従量課金制になるのですが、使っていなくても最低料金としてr7g.medium.searchインスタンスの8倍ほどかかってきます。
Knowledgeくらいのアクセス数であれば、オンデマンドインスタンスの方がスペック的にも十分ですし安価になります。
Bedrockはかなり安価で使用できる印象です。4月が高額になっていますが、これは性能評価としてLLM-as-a-Judgeを何度も実行したためです。LLM-as-a-Judgeとは、LLMの回答生成の評価をLLM自身に実行させる手法なのですが、一度の実行でどうしてもプロンプトの文量も多くなってしまうので高額になってしまいました。
1〜4月は開発コストも含んでいるので、5月以降が運用コストとしての料金になります。
紙面の都合上7月以降は載せていませんが、本稿を執筆している8月現在までのコストを見てみても、運用コストとしては高くても月額10ドル前後に落ち着いています。
Glueは2月こそ開発のためにジョブを何度も実行したので高額になっていますが、運用コストとしては月額1ドル程度です。
LambdaやAPI Gateway、SQSもAPI化や非同期化のため使用しているので記載していますが、これらは無料枠内におさまっており、コストはかかっていません。
Bedrockの各モデルアクセスのコストも表3に記載いたします。
| 1月 | 2月 | 3月 | 4月 | 5月 | 6月 | |
|---|---|---|---|---|---|---|
| Claude 3.5 Haiku | 0.26 | 0.55 | 0.00 | 0.22 | 0.03 | 0.00 |
| Claude 3.5 Sonnet | 4.03 | 14.71 | 43.99 | 2.69 | 9.44 | |
| Claude Sonnet 4 | 1.95 | 0.47 | ||||
| Amazon Titan Text Embeddings v2 | 0.22 | 0.02 | 0.01 | 0.02 | ||
| Amazon Rerank | 0.47 | 0.07 | 0.04 | 0.01 |
未導入の月は灰色のセルで示しています。
これを見ると、埋め込み(ベクトル変換)用で使っているAmazon Titan Text Embeddings v2、リランク用のAmazon Rerankはかなり安価なことが分かります。
特に埋め込みは、色々なユースケースで実施していますがそれでも月額1ドルもかかっていません。
さいごに
本稿では、2025年1月から5月にかけて社内サービス「Knowledge」にAIを導入した取り組みをご紹介しました。
2025年に入ってから、記事への閲覧数や記事の投稿数、投稿者の人数の統計をとってみるとこれまでになく高い傾きで右肩上がりに伸びています。
これには、「社内でGeminiが使えるようになったので、社員のAIに対する関心が高まりAIの知見を投稿する人が増えた」「情報共有に意欲的な新入社員が入ってきた」など複合的な理由が考えられますが、今回の取り組みもKnowledgeの活性化に良い影響を与え、その一因になったと確信しています。
検索機能の強化から記事作成の支援、さらにはAIチャットボットやエージェント機能まで、AIは社内の情報共有と活用を飛躍的に向上させる可能性を秘めています。
複雑なプロンプトの工夫や非同期処理の導入、コスト削減への配慮など、開発には様々な試行錯誤がありましたが、こうした取り組みを通じて得られた知見は、今後のAI活用における貴重な資産となりました。
企業のDXが加速する中、情報共有のあり方や社員の知識活用方法は常に変化しています。
私たちはこれからも、社員の皆さんが日々の業務で「手間」と感じる部分にAIを積極的に活用し、より情報の共有・活用が活発になるようなサービスを目指してまいります。
この記事が、皆さまのAI導入のヒントとなれば幸いです。
本記事に記載されているロゴ、システム名称、企業名称、製品名称は各社の登録商標または商標です。
執筆者紹介


連載コラム:エクサの生成AIチャレンジ日記
本コラムでは、エクサ社内における生成AIの活用に向けた技術的な取り組みと、実際の業務適用事例をご紹介いたします。生成AIによる業務効率化や新たな価値創造のヒントとなれば幸いです。
関連コラム

関連ソリューション






関連事例


お問い合わせ
CONTACT
Webからのお問い合わせ
エクサの最新情報と
セミナー案内を
お届けします
