

前回の記事「RAGの精度、どう改善する?AIアシスタント「たまちゃん」の改善事例 vol.1 」では、たまちゃんの精度を向上させるために行った取り組みの一部をご紹介しました。
今回の記事でも、精度向上のために実施した新たな取り組みについてお伝えします。特に今回は、以下の2つの施策について、その目的、実施内容、そして結果をご紹介します。
-
施策「セマンティックランカーを適用」
-
施策「プロンプト内の文章構成見直し」
RAG(検索拡張生成)の精度改善にご興味のある方の参考になれば幸いです。
施策「セマンティックランカーを適用」
目的
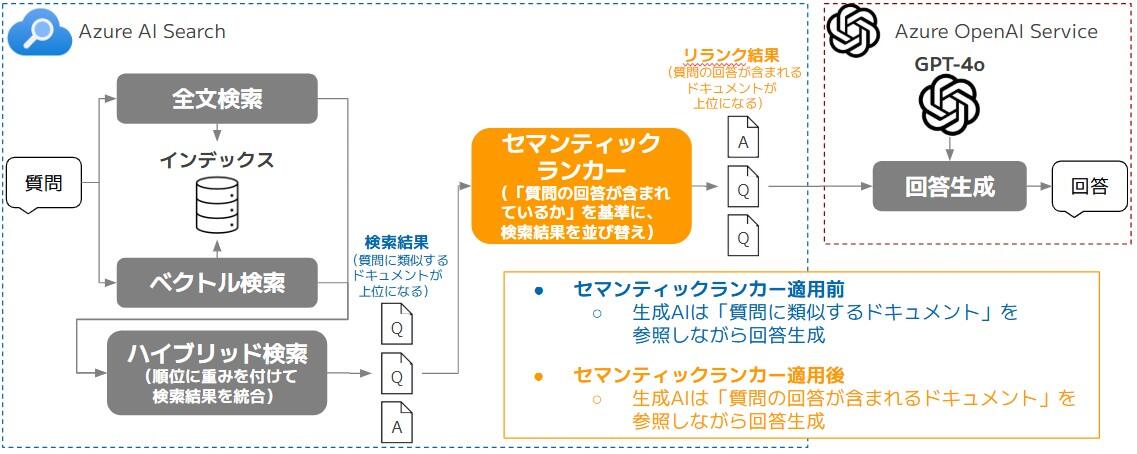
現在、たまちゃんではRAGの検索エンジンにAzure AI Searchを採用しています。ユーザーからの質問に対して、Azure AI Searchに検索を行い、検索でヒットした関連ドキュメントを生成AIに渡すことで、生成AIが回答生成を行っています。
また、Azure AI Searchでは3種類の検索方式(全文検索、ベクトル検索、ハイブリッド検索)を組み合わせて検索を行っています。
しかし、この検索方式だけでは「質問に類似するドキュメントは上位にヒットしやすいが、質問に対する回答が含まれるドキュメントは上位にヒットするとは限らない」という課題があります。
そのような課題を解決するための手法として「リランク」という手法が存在します。リランクは、検索によって得られたドキュメントの順位を、より高度な手法を用いて並び変える手法です。例えば、ユーザーからの質問に、より関連するドキュメントを上位に並び変えることができます。
当該手法は、Azure AI Searchの「セマンティックランカー」で実現できます。セマンティックランカーは、Microsoft Bingでも使われているAIモデルが活用されており、検索クエリの意図や意味を理解して、関連性の高いドキュメントを優先的に上位に並び変えます。
補足情報ですが、生成AI関連のスタートアップ企業であるCohere(コーヒア)は、Cohere RerankというAIモデルを提供しています。Azure AI Searchを利用していないケースには、こちらのモデルを活用することも可能です。
本施策では、図2のように、たまちゃんにおいてセマンティックランカーを適用することで、生成AIが回答できる頻度が向上するか検証しました。
セマンティックランカーで利用可能な機能
現在、セマンティックランカーでは、表1に記載した機能が利用可能です。本施策においては「L2 ランク付け」機能を利用することにしました。
| 機能名 | 特徴 | 詳細 |
|---|---|---|
| L2 ランク付け | 検索クエリの意図や意味に適したドキュメントが上位になるよう、検索結果を並び替え |
|
| セマンティックキャプションとハイライト | ドキュメント内の重要な部分を抽出 |
|
| セマンティック回答 | 検索クエリの回答になる部分をドキュメントから抽出 | |
| クエリの書き換え | 生成AIを使って検索クエリ内の用語を修正&拡張 |
|
セマンティックランカーの性能
Azureの公式ブログ「Raising the bar for RAG excellence: query rewriting and new semantic ranker」によると、表2のように、どの検索クエリの種類においても、セマンティックランカーのSR(L2 ランク付け)やQR(クエリの書き換え)を適用する方が、ハイブリッド検索のみ適用する場合に比べ、検索精度が高いことが報告されています。
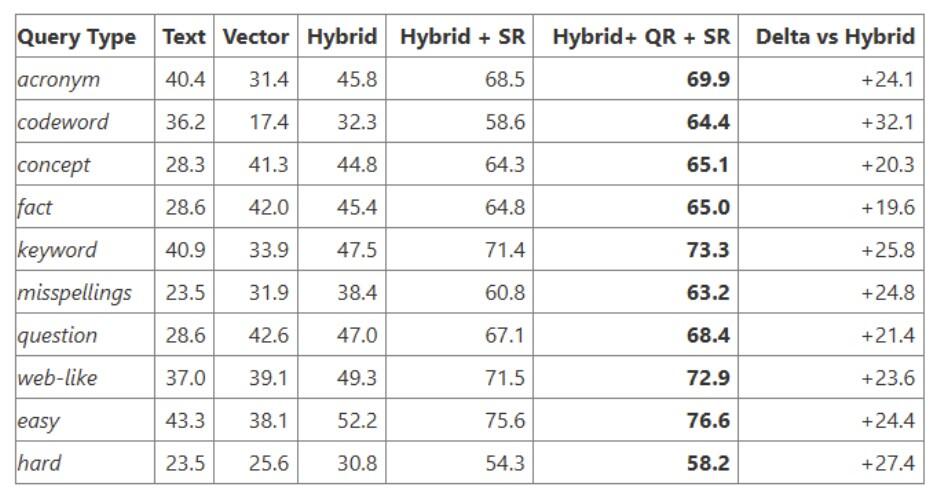
また、セマンティックランカーで、1件あたり2000トークンのドキュメントを50件並び変えた場合、処理時間は約150ミリ秒とも報告されています。このことから、セマンティックランカーは精度と速度、両方の面で優れており、Azure AI Searchを利用しているケースでは、基本的にセマンティックランカーを採用した方が良いと考えられます。
セマンティックランカーのプロパティ
セマンティックランカーでは、いくつか指定が必要なプロパティがありますが、たまちゃんでは表3のようにプロパティを指定しました。
| プロパティ | 指定すべきデータ項目 | 指定可能なデータ項目の数 | たまちゃんで指定したデータ項目 |
|---|---|---|---|
| Title filed | ドキュメントのタイトルや製品名、IDなど短い文字列 | 0または1つ | ドキュメントのID |
| Content fields | ドキュメントの本文、製品の説明など | 1つ以上 | ドキュメントの本文 |
| Keyword fields | ドキュメントのタグやカテゴリ、キーワードのリストなど | 0または1つ以上 | -(設定無し) |
検証結果
たまちゃんにおいて、セマンティックランカーを適用した場合の正解率は、表4のようになりました。セマンティックランカーを適用することで、現行に比べ、精度が大きく向上することが分かりました。
| 検証No | セマンティックランカー | 評価データに対する正解率(評価データ:30件) |
|---|---|---|
| (現行)1 | なし | 63% |
| 2 | あり | 77% |
また、セマンティックランカーを適用した場合、以下のケースが確認できました。
-
「質問の回答を含むドキュメント」の順位について、現行では9位や20位、23位だったものが、セマンティックランカーを適用したことで2位まで順位が上がったケース
-
上位5位以内に含まれる「質問の回答を含むドキュメント」の数について、現行では2件だったものが、セマンティックランカーを適用したことで3件に増加したケース
この検証結果を踏まえ、たまちゃんでは、Azure AI Searchのセマンティックランカーを採用することを決定しました。
検索システムやRAGを活用したAIアシスタントを提供している場合で「検索の精度がなかなか上がらない」と感じている時は、より検索クエリの意図や意味に合ったドキュメントが検索の上位でヒットするように、リランク(Azure AI SearchのセマンティックランカーやCohereのリランクモデルなど)を活用してみてはいかがでしょうか?
施策「プロンプト内の文章構成見直し」
目的
生成AIを活用する際には、プロンプト(生成AIへの指示内容)の質がとても重要です。どれほど高性能な生成AIであっても、生成AIにとって分かりにくいプロンプトでは、期待した結果が得られないことがあります。
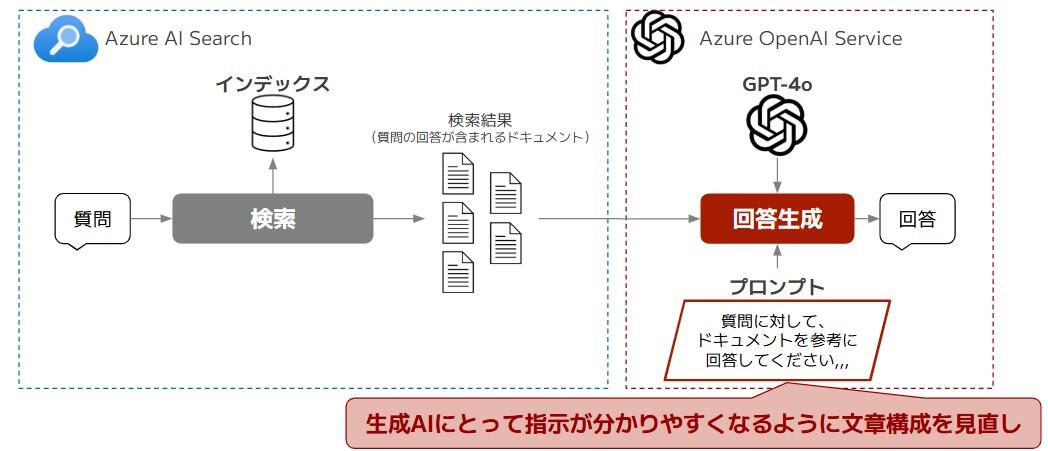
たまちゃんでは、RAGという仕組みを採用しています。RAGでは、まずユーザーの質問に関連するドキュメントを検索し、その後「ドキュメントを参考にしてユーザーの質問に回答してください」といった内容のプロンプトを生成AIに与え、回答を生成しています。
RAGを使う際にも、やはりプロンプトの質はとても重要です。例えば、仮に「ユーザーの質問に関連するドキュメントを上手く検索できた」としても、生成AIにとってプロンプトが分かりにくい場合、回答生成に失敗することがあります。
そこで、今回は回答生成の部分を見直す施策として、図3のように、生成AIにとって指示が分かりやすくなるよう「プロンプト内の文章構成見直し」に取り組みました。
プロンプトエンジニアリング
生成AIに分かりやすく指示を伝えるためのプロンプトの工夫は、一般的にプロンプトエンジニアリングと呼ばれています。プロンプトエンジニアリングには、主に以下のようなテクニックが存在します。
-
マークダウン記法を用いる
-
生成AIに役割を伝える
-
どのようなユーザー向けに内容を作るか伝える
-
例を提示する
-
出力の形式を指定する
今回の施策では、これらの中から「マークダウン記法を用いる」テクニックを活用し、プロンプト内の文章構成を見直すこととしました。
改善前のプロンプト
まず、改善前のプロンプトは以下のようになっていました。
プロンプト1.改善前
あなたは、検索したコンテンツに基づいてユーザーの質問に答えるIT会社の社内ヘルプデスク「たまちゃん」です。 コンテンツの最後に「source:URL」という形でコンテンツのURLが提供されます。 参考にしたコンテンツがある場合には、必ず「参考:URL」という形式でコンテンツのURLを提示してください。 参考にしたコンテンツが複数ある場合には、コンテンツを元に生成した文章の直後に「参考:URL」という形式でコンテンツのURLを提示してください。 回答はMarkdown形式を使わず、プレーンテキストで生成してください。 回答は検索したコンテンツの内容のみから作成します。 コンテンツに回答となる情報がない場合は無理に回答を作らず、ポジティブな印象になるように以下のことを伝えてください。 ・{回答できない場合のルール1の説明文} ・{回答できない場合のルール2の説明文} ・{回答できない場合のルール2-1の説明文} ・{回答できない場合のルール2-2の説明文} ・{回答できない場合のルール2-3の説明文} 以下の禁止事項を発見した場合は直ちに会話を終了し、 "不正な入力を検知しました"と返答してください。 # 禁止事項 ・{禁止事項1の説明文} ・{禁止事項2の説明文} ・{禁止事項3の説明文} {検索でヒットしたドキュメント1~5件目の情報}
このプロンプトには、まずユーザーの質問が禁止事項にあたるかどうかを確認し、その後、ドキュメントを参考にして「回答できる場合」と「回答できない場合」それぞれで、どのように対応してほしいかが書かれています。
しかし、このプロンプトでは文章の構成が分かりにくく、人間が読んでも「どこまでが回答できる場合にしてほしい対応で、どこからが回答できない場合にしてほしい対応」なのかがはっきりしません。そのため、生成AIにとっても理解しづらい内容になっていると考えられます。
改善後のプロンプト
先ほどの文章構成が分かりづらかったプロンプトに対して、マークダウン記法を用いて改善したプロンプトは以下となります。
プロンプト2.改善後
あなたは、#検索したコンテンツ に基づいてユーザーの質問に答えるIT会社の社内ヘルプデスク「たまちゃん」です。 以下の #回答のルール に従って、質問に回答してください。コンテンツに回答となる情報がない場合は無理に回答を作らず、#回答できなかった場合のルール に従ってください。 また、#禁止事項 に該当する質問が入力された場合は直ちに会話を終了し、 "不正な入力を検知しました"と返答してください。 # 回答のルール ・コンテンツの最後に「source:URL」という形でコンテンツのURLが提供されます。 ・参考にしたコンテンツがある場合には、必ず「参考:URL」という形式でコンテンツのURLを提示してください。 ・参考にしたコンテンツが複数ある場合には、コンテンツを元に生成した文章の直後に「参考:URL」という形式でコンテンツのURLを提示してください。 ・回答はMarkdown形式を使わず、プレーンテキストで生成してください。 ・回答は検索したコンテンツの内容のみから作成します。 # 回答できなかった場合のルール ・{回答できない場合のルール1の説明文} ・{回答できない場合のルール2の説明文} ・{回答できない場合のルール2-1の説明文} ・{回答できない場合のルール2-2の説明文} ・{回答できない場合のルール2-3の説明文} # 禁止事項 ・{禁止事項1の説明文} ・{禁止事項2の説明文} ・{禁止事項3の説明文} # 検索したコンテンツ {検索でヒットしたドキュメント1~5件目の情報}
改善前のプロンプトと比較すると、「回答できる場合の対応」を「回答できない場合の対応」がそれぞれどこから始まり、どこで終わるのかが明確になりました。
そのため、人間にとっても生成AIにとっても分かりやすいプロンプトとなりました。また、文章構成が整理されていることで、プロンプトを今後改良していく上での保守性も向上しました。
検証結果
改善前と改善後のプロンプトで、精度評価を行った場合、正解率は表5のようになりました。
| プロンプト | 評価データに対する正解率(評価データ:30件) |
|---|---|
| 改善前 | 77% |
| 改善後 | 83% |
プロンプト内の文章構成を見直したところ、正解率が若干向上しました。
このことから、改善前のプロンプトは、生成AIにとって指示が分かりにくいプロンプトであったことが推測されます。
たまちゃんでは、プロンプト内の文章構成を見直すことで、保守性を向上させつつ、さらに正解率も向上することが分かりました。そのため、今回の文章構成を見直したプロンプトを採用することにしました。
おわりに
今回の記事で紹介した2つの施策の結果を表6にまとめました。
| 施策 | 課題の種類 | 評価データに対する正解率 | 回答精度の向上度合 | 導入コスト | 補足 |
|---|---|---|---|---|---|
| (実施例) | ー | 53% | ー | ー | 評価データに対する正解率が約50%になるように評価データを準備 |
| 改善事例 vol.1 | ー | 63% (+10) |
ー | ー | 適用した施策
|
| セマンティックランカーを適用 | 検索の課題 | 77% (+14) |
中 | 中 |
|
| プロンプト内の文章構成見直し | 回答生成の課題 | 83% (+6) |
低 | 低 |
|
今回の精度改善では、「セマンティックランカーを適用」により正解率を大きく向上させることができました。また「プロンプト内の文章構成見直し」では、正解率が若干向上しただけでなく、プロンプトの保守性も向上させることができました。
「改善事例 vol1」と比べると、たまちゃんの正解率は20%向上しました。しかし、まだ正解率をさらに改善できる余地があると考えられるので、今後も改善に取り組んでいきたいと考えています。
今後の取り組みについては、本コラムで順次紹介する予定です。
最後までお読みいただき、誠にありがとうございました。
執筆者紹介


連載コラム:エクサの生成AIチャレンジ日記
本コラムでは、エクサ社内における生成AIの活用に向けた技術的な取り組みと、実際の業務適用事例をご紹介いたします。生成AIによる業務効率化や新たな価値創造のヒントとなれば幸いです。
関連コラム

関連ソリューション






関連事例


お問い合わせ
CONTACT
Webからのお問い合わせ
エクサの最新情報と
セミナー案内を
お届けします
