

はじめに
前回の記事「AIアシスタント「たまちゃん」をより良いサービスにするために」では、たまちゃんの課題を「検索」「回答生成」「UI/UX(ユーザーインターフェース/ユーザーエクスペリエンス)」の3つに分類し、マインドマップを使って具体的な問題点と改善タスクを洗い出したプロセスをご紹介しました。
課題とタスクが見えてきたことで、いよいよ本格的な精度改善のフェーズに入ります。リストアップしたタスクの中から、効果の大きさや実現の難易度、他のタスクへの影響などを考慮して優先順位をつけ、計画的に改善策を実施していくことにしました。
今回の記事では、精度改善策の中から以下の2つの施策について、その目的、実施内容、そして結果をご紹介します。
-
施策「同義語辞書の登録」
-
施策「検索エンジンから取得するドキュメント数を増やす」
RAG(検索拡張生成)の精度改善にご興味のある方の参考になれば幸いです。
施策「同義語辞書の登録」
目的
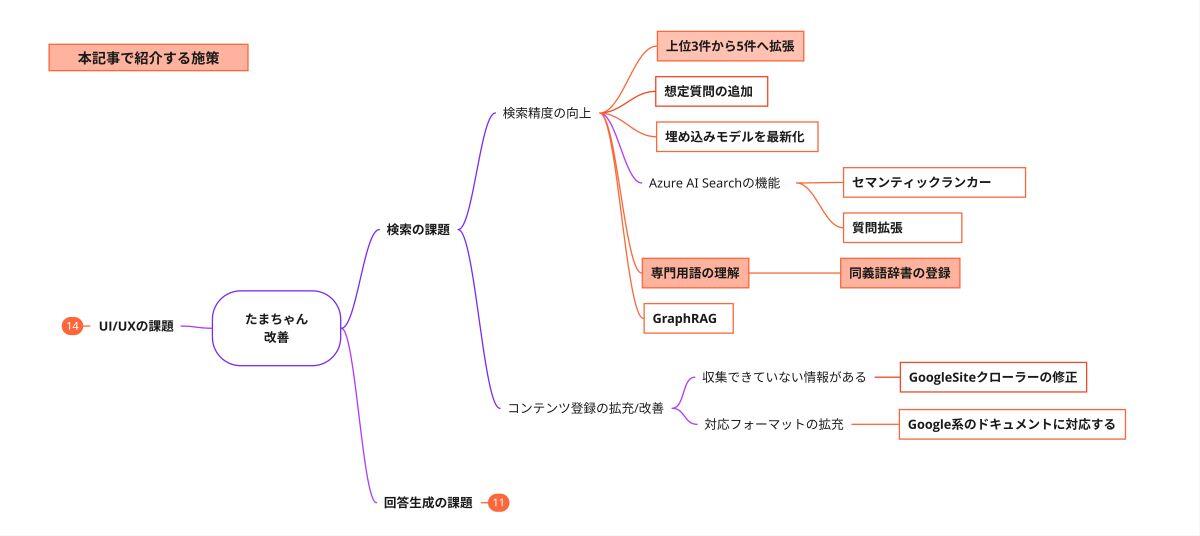
たまちゃんは、質問に関連する社内ドキュメントを検索し、その内容を元に回答を生成します。たまちゃんのシステム構成を図2に示します。
検索エンジンとしてMicrosoft Azure AI Search を利用しており、検索時には「ベクトル検索」と「全文検索」を組み合わせた「ハイブリッド検索」を行っています。それぞれの検索方法の特徴を表1にまとめました。
| 検索方式 | 仕組み | メリット | デメリット |
|---|---|---|---|
| 全文検索 | 検索クエリで指定されたキーワードが含まれているドキュメントを探す | キーワードに合致するものは正確に見つかる | 言い換えや類義語、意味が近いものは見逃しやすい |
| ベクトル検索 | 埋め込みモデルを使用してテキストをベクトル化(数値化)する技術を用いることで、検索クエリと類似度が高いドキュメントを探す | 意味的に関連する情報を幅広く見つけられる | 埋め込みモデルが学習していない専門用語はうまく扱えない場合がある |
| ハイブリッド検索 | 別々の検索結果(全文検索とベクトル検索)を1つの検索結果に統合する | 正確かつ網羅的な検索結果を得やすい | システムがやや複雑になる場合がある |
たまちゃんで採用しているハイブリッド検索ではベクトル検索と全文検索の長所を活かしています。しかし、社内で使われている言葉の中には、ベクトル検索ではうまく検索できないような専門的な表現や、全文検索でもうまく検索できないような独自の略語や同義語などが含まれています。ベクトル検索に利用する埋め込みモデルの学習を行うのも解決策の1つですが、学習データの準備など大きなコストがかかります。
そこで、今回は全文検索の精度を高めるために「同義語辞書」をAzure AI Searchに登録することにしました。同義語辞書の登録はAzure AI Searchの機能として実装されており、比較的容易に試すことができます。同義語辞書として専門的な表現や同義語を登録して全文検索の精度を上げることができれば、ハイブリッド検索の精度向上にもつながる可能性があります。
全文検索への同義語辞書の適用
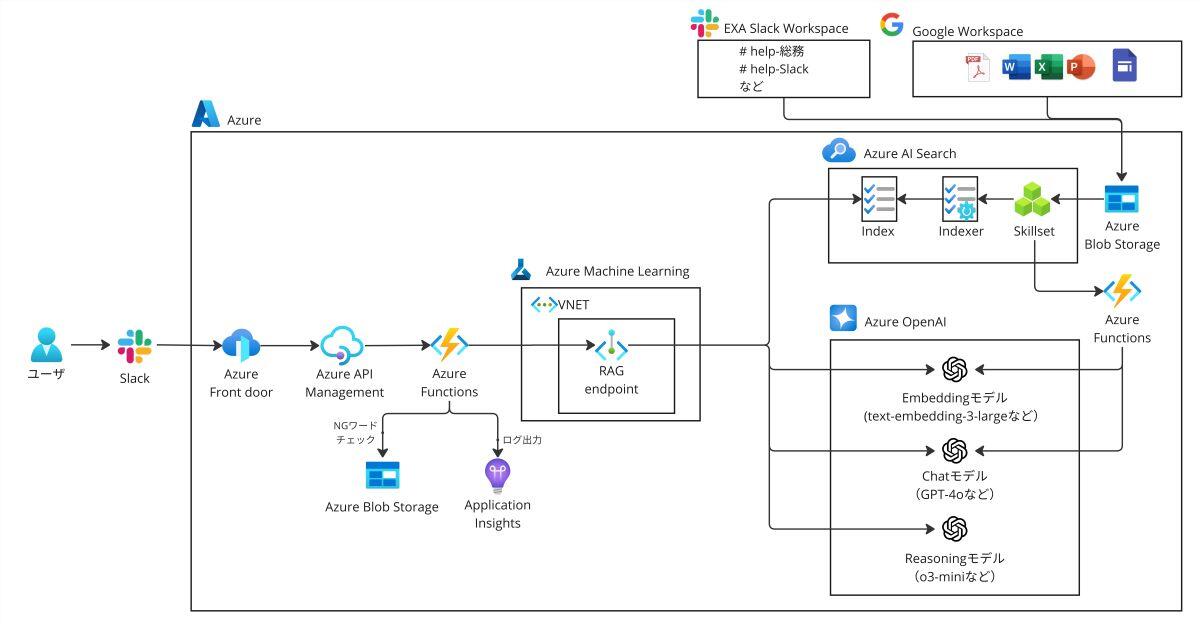
たまちゃんにおいて、同義語辞書を全文検索に適用して、最終的に回答生成を行うまでの流れを図3に示しました。
同義語辞書に登録している同義語の例を以下の表2に示しました。たまちゃんでは合計69件の同義語を登録しています。
| 単語 | 同義語1 | 同義語2 | 同義語3 |
|---|---|---|---|
| 産前産後休暇 | 産休 | 出産休暇 | |
| 定期券 | 通勤定期券 | 通勤費 | 通勤費補助金 |
| F・ウェルネス休暇 | エフウェルネス休暇 | F休 | エフ休 |
検証結果
同義語辞書を登録した後、評価ツール「RAGAS」を使って精度評価を行った結果を表3に示しました。同義語辞書がない場合と比較して、検索精度(Context Recall: 検索したドキュメントに正解の文章が含まれるか)は0.34から0.45へと向上しました(検索精度についてはコラム『AIアシスタント「たまちゃん」をどうやって評価する?~RAGの精度評価の仕組み~』を参照ください)。これは、同義語辞書によって全文検索が強化され、関連ドキュメントを見つけやすくなったことを示しています。
しかし一方で、評価データ30件に対する正解率は53%から57%へと微増にとどまりました。分析を進めると、「正解のドキュメントを検索できているにも関わらず、質問に回答できないケース」が依然として存在することが分かりました。
| 検証No | 検証内容 | 検索したドキュメントに正解の文章が含まれるか(*) | 評価データに対する正解率 (評価データ:30件) |
|---|---|---|---|
| 1 | 同義語辞書なし | 0.34 | 53% |
| 2 | 同義語辞書あり | 0.45 | 57% |
(*) スコアは0~1の範囲で、1に近いほど検索精度が高いことを示す
例えば、「F休の申請方法を教えて」という質問に対し、同義語辞書の助けもあって「F・ウェルネス休暇」に関する人事の規定ページが検索結果の上位に含まれるようになりました。しかし、たまちゃんは「すみません、F休の申請方法に関する情報を見つけられませんでした」と回答してしまいます。
これは、同義語辞書が検索時にしか参照されず、回答生成を行う際にはその同義語関係(F休=F・ウェルネス休暇)を理解していないことが原因であると考えられました。
今回の施策「同義語辞書の登録」では、検索時に同義語辞書を参照できるようにしたことで検索精度が向上しましたが、回答生成時の同義語理解に課題が残る結果となりました。
施策「検索エンジンから取得するドキュメント数を増やす」
目的
たまちゃんではRAG(Retrieval Augmented Generation)を採用しています。
ユーザからの質問に対して、検索エンジンから関連ドキュメントを取得し、取得した関連ドキュメントをプロンプトに埋め込むことで、生成AIが関連ドキュメントを参照しながら回答を生成する、という流れになっています。この流れにおいて、検索エンジンから取得する関連ドキュメントの数は、回答生成に影響する重要なパラメータの1つです。
現状は、検索エンジンへの検索でヒットした上位3件分の関連ドキュメントを取得し、生成AIに渡していますが、例えば、質問に対する回答が含まれる関連ドキュメントが、上位4位や5位に存在する場合、これらの関連ドキュメントが生成AIに渡されず、回答生成に失敗します。
そこで、本施策では、検索エンジンから取得する関連ドキュメントの数を増やすことで、生成AIが回答できる頻度が向上するか検証しました。
まず、たまちゃんでは、検索エンジンにAzure AI Searchを採用しています。Azure AI Searchでは3種類の検索方式(全文検索、ベクトル検索、ハイブリッド検索)を組み合わせて利用しています。
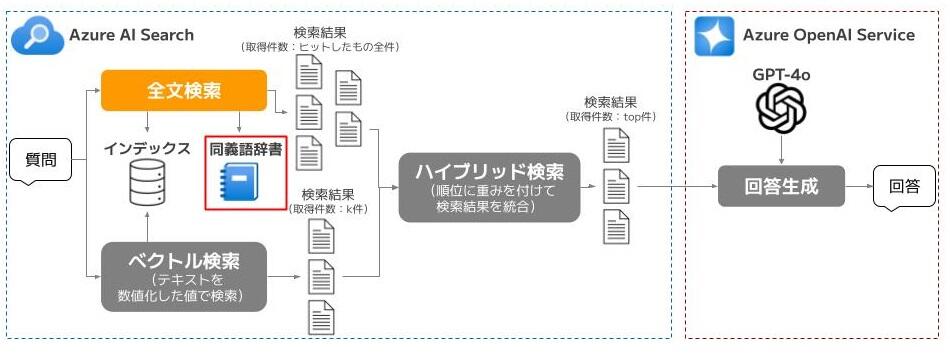
また、Azure AI Searchにおいて、検索エンジンから取得する関連ドキュメントの数を増やす場合、図4のように、k(ベクトル検索時に何件取得するか)とtop(ハイブリッド検索時に何件取得するか)という2種類のパラメータが設定可能です。本施策ではこの2種類のパラメータを変化させながら、回答の精度が向上するか検証を行いました。
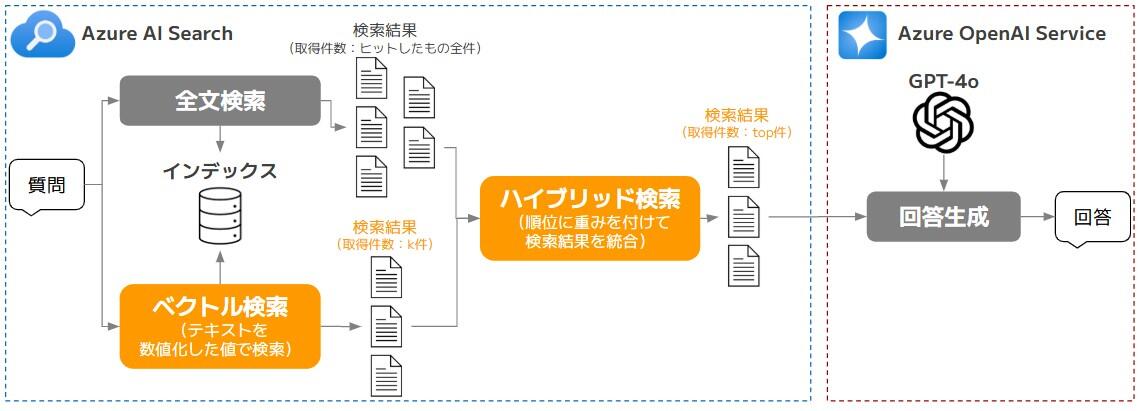
ドキュメントを増やす場合の注意点
検索エンジンから取得する関連ドキュメントの数を増やす場合、プロンプトに埋め込むドキュメントの量も多くなります。そのため、いくつか注意が必要です。
例えば、先行研究「LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression」では、図5のように、プロンプト内に質問に無関係な情報や冗長な情報が含まれるドキュメントが増えていくことで、回答品質が低下していくことを示しました。特にQA対応(Multi-Document QA)は、コーディング支援(Code Completion)や要約(Summarization)に比べ、回答品質が低下しやすい傾向があります。
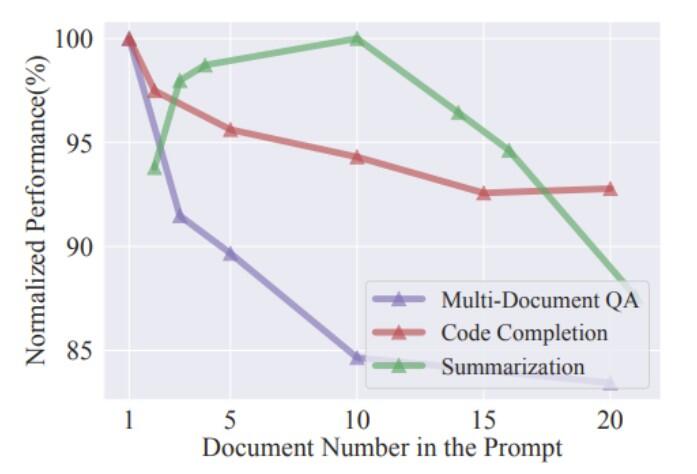
引用:「LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression」
また、表4のように、プロンプト内に埋め込むドキュメント数に比例してトークン数が増加することで、生成AIの利用料金が高くなることにも注意が必要です。
| プロンプトに埋め込む ドキュメント数 | トークン数 (概算) | 利用料金 (GPT-4o) |
|---|---|---|
| 3 | 2,500 | 2円 |
| 5 | 4,000 | 3円 |
| 10 | 8,000 | 6円 |
検証結果
たまちゃんにおいて、検索エンジン(Azure AI Search)から取得する時のパラメータ、kとtopを変化させた場合、正解率(回答できた件数の割合)は表5のようになりました。
| 検証No | k | top | トークン数 (概算) | 利用料金 (GPT-4o) | 評価データに対する正解率 (評価データ:30件) |
|---|---|---|---|---|---|
| (現行)1 | 3 | 3 | 2,500 | 2円 | 57% |
| 2 | 5 | 5 | 4,000 | 3円 | 63% |
| 3 | 10 | 5 | 4,000 | 3円 | 67% |
| 4 | 50 | 5 | 4,000 | 3円 | 63% |
| 5 | 10 | 10 | 8,000 | 6円 | 70% |
まず、kとtopを現状の値から大きくすることで精度が良くなる傾向があります。また、kよりもtopを大きくした方が精度が良くなりやすい傾向もありました。さらに、topは3,5,10の内、10が最も精度が良くなることが分かりました。
一方で、利用料金と精度のバランス、パラメータのシンプルさを考慮し、今回はオレンジ色の検証No2のケース(kとtopが共に5)を採用することとしました。
おわりに
今回の記事で紹介した2つの施策の結果を表6にまとめました。
| 施策 | 課題の種類 | 評価データに対する正解率 | 正解率の向上度合 | 導入コスト | 補足 |
|---|---|---|---|---|---|
| (実施前) | ー | 53% | ー | ー | |
| 同義語辞書の登録 | 検索の課題 | 57% (+4) |
低 | 中 |
|
| 検索エンジンから取得するドキュメント数を増やす | 検索の課題 | 63% (+6) |
低 | 低 |
|
今回の精度改善では、「同義語辞書の登録」により検索精度は向上したものの、回答生成時の同義語理解に課題が残りました。一方、「検索エンジンから取得するドキュメント数を増やす」施策では、コストとのバランスを考慮しつつ、評価データに対する正解率を向上させることができました。
一方で、たまちゃんの評価データに対する正解率はまだ63%と高くない状態です。今回の結果を踏まえて、更なる精度向上に向けて取り組んでいく必要があることがわかりました。
以降の取り組みについては、本コラムで順次紹介する予定です。
最後までお読みいただき、誠にありがとうございました。
執筆者紹介



連載コラム:エクサの生成AIチャレンジ日記
本コラムでは、エクサ社内における生成AIの活用に向けた技術的な取り組みと、実際の業務適用事例をご紹介いたします。生成AIによる業務効率化や新たな価値創造のヒントとなれば幸いです。
関連コラム

関連ソリューション






関連事例


お問い合わせ
CONTACT
Webからのお問い合わせ
エクサの最新情報と
セミナー案内を
お届けします
