

はじめに
前回の記事「RAGの精度、どう改善する?AIアシスタント「たまちゃん」の改善事例 vol.2」では、たまちゃんの精度を向上させるために行った取り組みの一部をご紹介しました。
今回は、以下の施策について、その目的、実施内容、そして結果をご紹介します。
-
施策「チャンクサイズの調整」
-
施策「埋め込みモデルの最新化」
RAG(検索拡張生成)の精度改善にご興味のある方の参考になれば幸いです。
施策「チャンクサイズの調整」
目的
RAGシステムでは、ユーザーからの質問に関連する情報を効率的に検索し、LLM(大規模言語モデル)に提供するために、ドキュメントを事前に小さな単位に分割して(チャンキングして)保存します。この分割された個々の情報単位を「チャンク(chunk)」と言います。
では、なぜチャンクサイズの調整が重要なのでしょうか。それは、チャンクサイズが不適切だと、以下のような問題が発生する可能性があるからです。
-
チャンクサイズが大きすぎる場合: LLMが一度に処理できる情報量には限りがあります。チャンクサイズが大きすぎると、LLMが情報を読み取りきれず、重要な情報を見落としてしまう可能性があります。
-
チャンクサイズが小さすぎる場合: 情報が断片的になりすぎてしまい、文脈が途切れてしまいます。その結果、LLMが質問の意図や背景を正確に理解できず、適切な回答を生成できなくなる可能性があります。
このように、RAGシステムの性能を最大限に引き出すためには、コンテンツの特性に応じてチャンクサイズを適切に調整することが不可欠です。
本施策では、たまちゃんの精度と費用のバランスの取れたチャンクサイズを明らかにすることを目的としてチャンクサイズの検証を行いました。
チャンク分割方法
チャンク分割にはいくつかの手法が存在します。代表的な手法を表1にまとめました。
| 種類 | 概要 | 特徴 |
|---|---|---|
| 固定長チャンキング | 文書を固定長のチャンクに分割。例えば、特定の文字数やトークン数ごとに分割する | シンプルで実装が容易だが、文脈を無視する可能性がある |
| 再帰的チャンキング | ピリオド(。)、クエスチョンマーク(?)などのセパレーター(区切り文字)を使用して文書を再帰的に分割する | 文書の構造を考慮し、より意味のあるチャンクを作成できる |
| 文書ベースのチャンキング | 文書の構造(例: MarkdownやPythonコード)に基づいて分割する | 文書の特性を活かした分割が可能。コンテンツがHTMLやMarkdownである場合には有効 |
| セマンティックチャンキング | 文の類似度に基づいて分割。隣接する文の類似度が低い箇所で分割する | テキストの意味や文脈を考慮した分割が可能 |
たまちゃんでは、シンプルで実装が容易な固定長チャンキングを採用しています。
固定長チャンキングにおける「オーバーラップ」
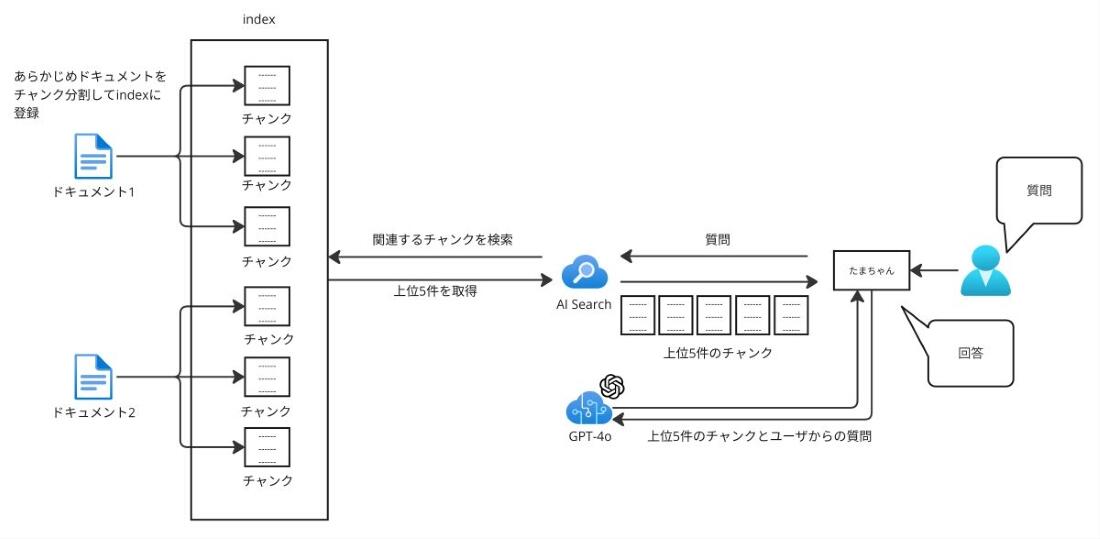
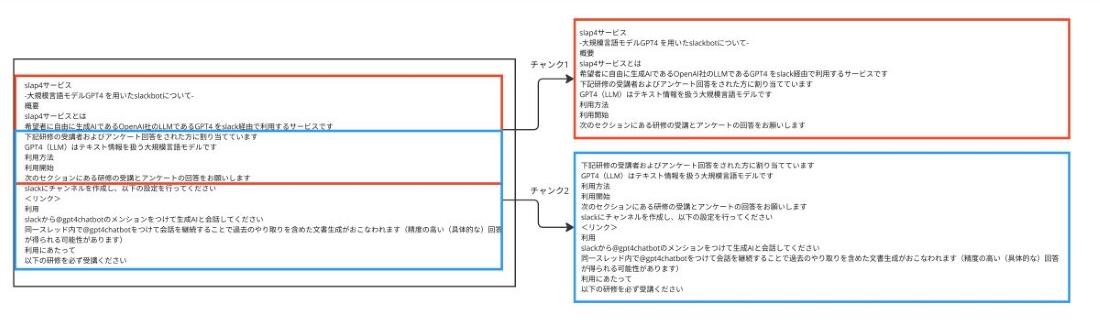
固定長チャンキングを用いる際、隣接するチャンク間で一部の情報を重複させる「オーバーラップ」というテクニックがあります。 例えば、あるチャンクの末尾部分を、次のチャンクの先頭部分にも含めるようにします。これにより、チャンクの境界で情報が完全に途切れてしまうことを防ぎ、文脈の連続性を保つ効果が期待できます。
たまちゃんではAzure AI Searchの機能を利用し、このオーバーラップを持たせた形でチャンク分割を行っています。
チャンクサイズの調整
従来のたまちゃんでは、チャンクサイズを900文字、オーバーラップを100文字として設定していました。 今回の検証では、まず適切なチャンクサイズの目安を探るため、情報ソースであるGoogleサイトとSlackのドキュメント1ページあたり(Slackの場合は1スレッドあたり)の文字数を調査しました。(Google Drive内のファイルは、形式やページ数が多岐にわたるため、今回の初期調査対象からは除外しました。)
調査結果は以下の通りです。
| 平均文字数 | 最大文字数 | 最小文字数 | |
|---|---|---|---|
| Googleサイト(1ページあたり) | 1525.1 | 23600 | 63 |
| Slack(1スレッドあたり) | 529.8 | 16490 | 5 |
この結果から、特にGoogleサイトの平均文字数を参考に、以下の4種類のチャンクサイズで精度を比較検証することにしました。
-
900文字
-
1500文字
-
3000文字
-
5000文字
オーバーラップについては、各チャンクサイズの3割程度に設定しました。
検証結果
各チャンクサイズで評価した際の、平均トークン数、料金、評価データに対する正解率を比較しました。結果は以下の表の通りです。
| 検証No | チャンクサイズ | オーバーラップ | 平均トークン数(*1) | 料金(*2) | 評価データに対する正解率 (評価データ:45件) |
|---|---|---|---|---|---|
| 1 | 900文字 | 100文字 | 4599 | 3.44円 | 60% |
| 2 | 1500文字 | 450文字 | 6253 | 4.67円 | 60% |
| 3 | 3000文字 | 900文字 | 8600 | 6.43円 | 69% |
| 4 | 5000文字 | 1500文字 | 10928 | 8.17円 | 67% |
(*1)評価データでRAGフロー全体を実行した際の入力トークン数から算出
(*2)(*1)の入力トークンから算出(出力トークンは計算対象外)
検証の結果、チャンクサイズを3000文字(オーバーラップ900文字)とした場合に、評価データに対する正解率が最も高くなりました。
回答内容の改善事例
チャンクサイズを調整したことで、従来よりも詳細かつ適切な情報を提供できるようになった事例が見られました。
事例:質問「住所変更に必要な手続きを教えて」への回答
変更前の回答
住所変更に必要な手続きは以下の通りです。 1. 人事システムにログインします。 2. 『個人情報』をクリックします。 3. 『連絡先情報』をクリックします。 4. 新規登録の場合は『住所』欄右上のボタンをクリックします。 申請内容に不備がある場合、差戻となり再申請が必要です。また、住民票住所は住民票に記載されている表記通りに登録してください。表記が異なるとマイナンバーカードで医療機関等を受診した際に影響が出る可能性があります。 参考:<<人事部のサイトのURL>>
変更後の回答
住所変更に必要な手続きは以下の通りです。 1. 人事システムにログインします。 2. 『個人情報』をクリックします。 3. 『連絡先情報』をクリックします。 4. 新規登録の場合は『住所』欄右上のボタンをクリックし、変更する場合は各住所の右上のマークをクリックします。 5. 各項目を選択または入力します。 - 国、タイプ(現住所、住民票住所、緊急連絡先)、開始日、郵便番号、市区町村コード、都道府県、市区町村、住所1、住所2、電話番号などを入力します。 6. 各項目入力後、右上のボタンをクリックして完了です。 注意事項として、住民票に記載されている住所を正確に登録することが求められます。表記が異なるとマイナンバーカードでの医療機関受診などに影響が出る可能性があります。 参考:<<人事部のサイトのURL>>
変更前は住所変更の手順1から4のみが提示されていましたが、変更後は手順1から6まですべての手順を提示できるようになり、住所変更の場合の手順や入力項目についても具体的に案内できるようになりました。
施策「埋め込みモデルの最新化」
目的
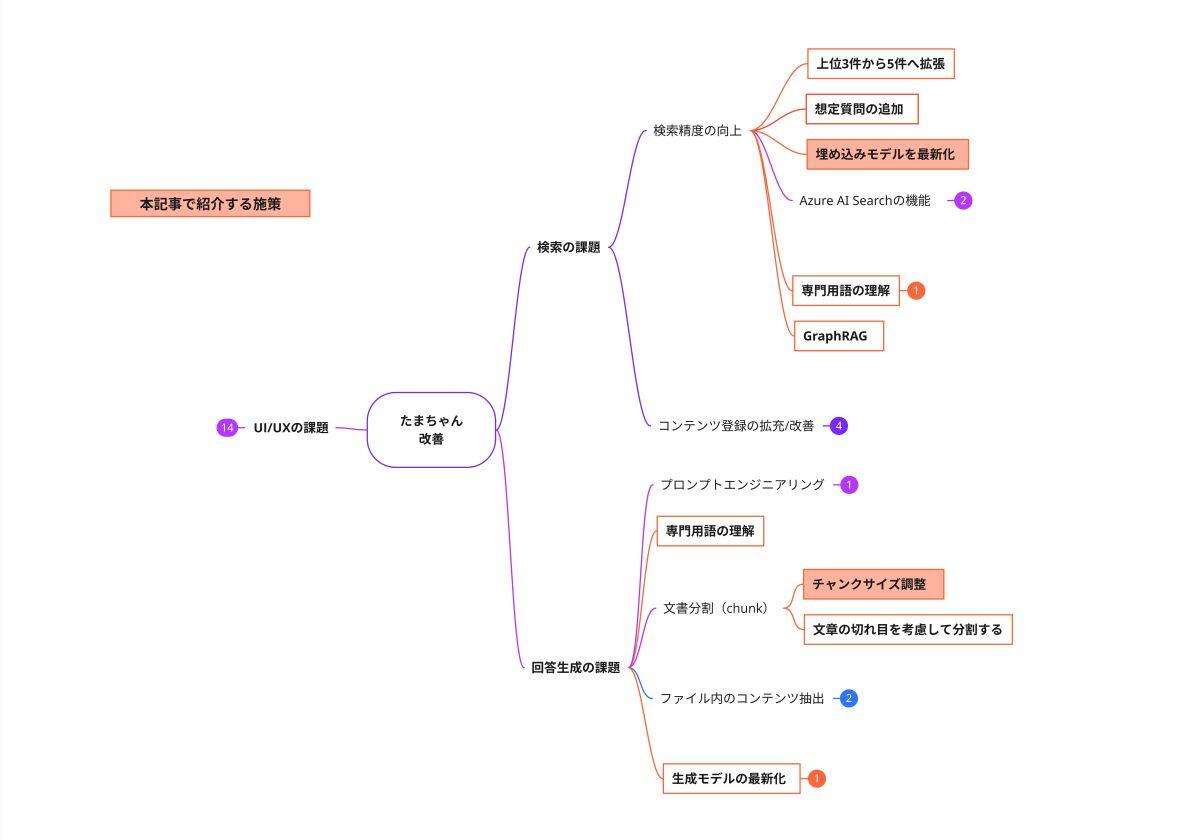
現在、たまちゃんではRAG(Retrieval Augmented Generation)の検索エンジンとして、Azure AI Searchを採用しています。また、Azure AI Searchでは3種類の検索方式(全文検索、ベクトル検索、ハイブリッド検索)を組み合わせて検索を行っています。
特にベクトル検索では、埋め込みモデルを使って、テキストをベクトル(数値)に変換することで、検索クエリに類似度が高いドキュメントを検索しています。
現在は、Azure OpenAI Serviceで提供されている「text-embedding-ada-002」というモデルを使用していますが、このモデルはOpenAIが2022年に発表した少し古いモデルとなっています。その後、OpenAIは2024年に新しい埋め込みモデルを2種類発表し、これらのモデルがAzure OpenAI Serviceで利用可能になっています。
そこで今回は、図4のように、ベクトル検索に使用する埋め込みモデルを「text-embedding-ada-002」から新しい埋め込みモデルに変更することで、たまちゃんの回答精度がどれだけ良くなるかを検証することにしました。
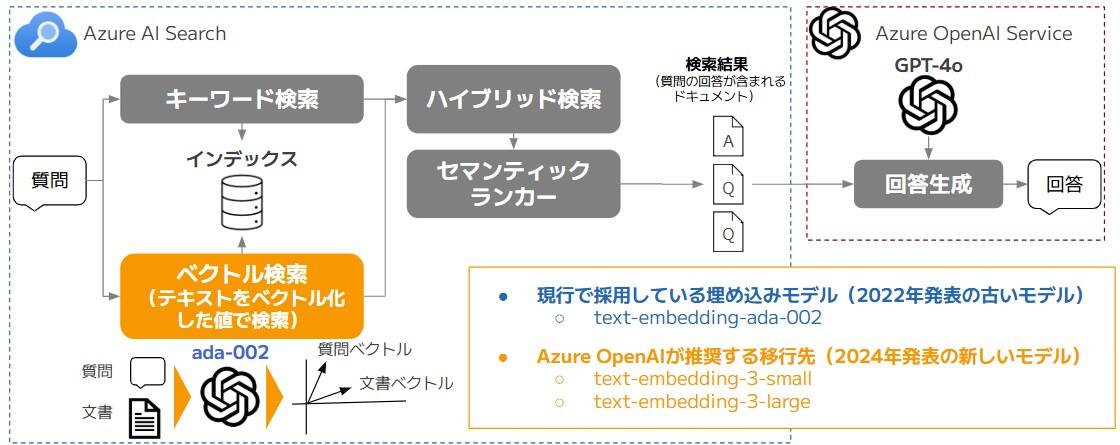
Azure OpenAI Serviceで利用可能な埋め込みモデル
現在、Azure OpenAI Serviceでは、表4に記した3種類の埋め込みモデルが利用可能となっています。この内、「text-embedding-ada-002」は「text-embedding-3-small」または「text-embedding-3-large」への移行が推奨されています。
| # | モデル名 | モデルの発表日 (OpenAI公式ブログの日付) | 出力されるベクトルの次元数 | 料金 (1000トークンあたり) | 提供終了日 (Azure OpenAI Service) | 備考 |
|---|---|---|---|---|---|---|
| 1 | text-embedding-ada-002 | 2022/12/15 | 1536 | ¥0.015099 | 2025/10/3以降 | Azureは、#2または#3のモデルへの移行を推奨 |
| 2 | text-embedding-3-small | 2024/1/25 | 1~1536 (※) |
¥0.003020 | 利用料金やベクトルDBの容量を削減したいケースに有効 | |
| 3 | text-embedding-3-large | 1~3072 (※) |
¥0.019629 | - |
※モデル呼び出し時のパラメータで、出力されるベクトルの次元数を指定可能
マトリョーシカ表現学習とは
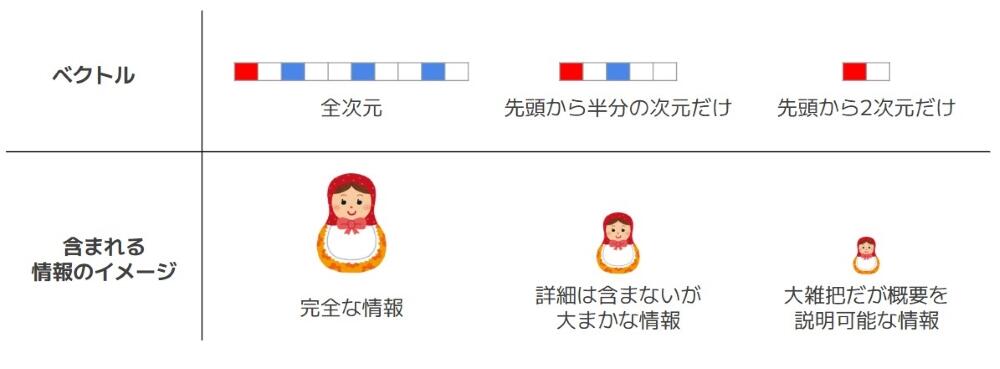
「text-embedding-3-small」と「text-embedding-3-large」は、従来の埋め込みモデルと異なり、出力されるベクトルの次元数が指定可能なモデルとなっています。これはマトリョーシカ表現というフレームワークを活用して学習が行われたモデルであるためです。マトリョーシカ表現で学習されたモデルは、出力されるベクトルの内、先頭の一部だけ切り出しても、大まか情報が得られるようなベクトルを出力するようになります。
マトリョーシカ表現学習のコンセプトは、「ベクトルの前半に大雑把な情報、後半に詳細な情報が含まれているようなベクトルを作る」ことです。図5は、マトリョーシカ表現学習で作成されるベクトルのイメージとなります。全次元のベクトルでは完全な情報が得られますが、先頭から一部切り出したベクトルだけでも大まかな情報を得ることができます。
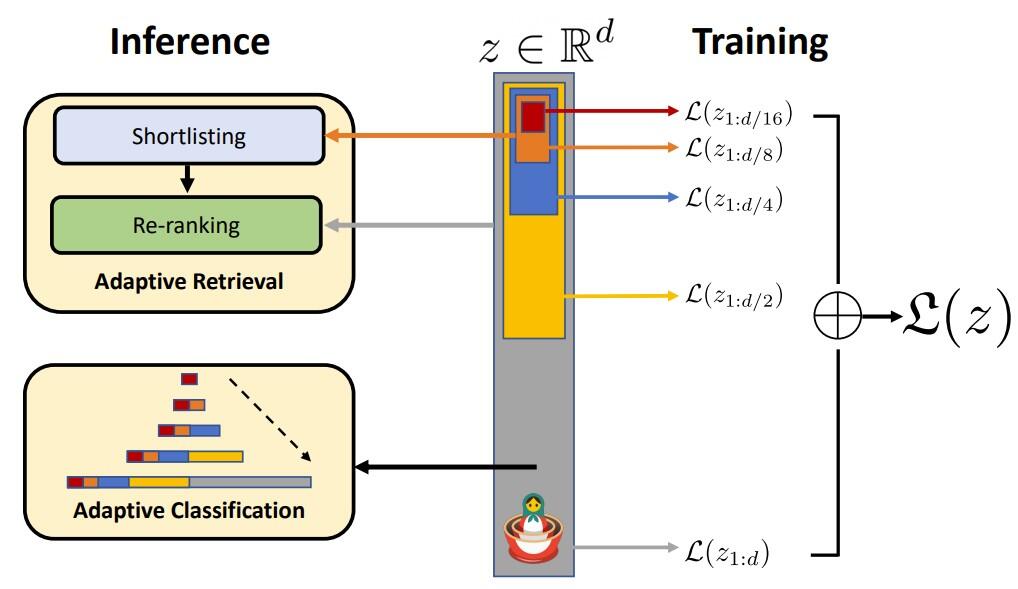
次に、マトリョーシカ表現学習でどのようにモデルの学習を行うかをざっくりご紹介します。マトリョーシカ表現学習は図6のような流れでモデルの学習を行います。
真ん中の灰色の縦棒が全次元のベクトルとなっており、黄色の縦棒が半分の次元数のベクトル、青色の縦棒が¼の次元数のベクトル、オレンジ色が⅛の次元数のベクトルとなっております。
従来のモデル学習では、灰色の縦棒の全次元のベクトルに対してのみ損失(正解データとモデルの予測結果の誤差)を計算し、モデルのパラメータを更新していました。
しかし、マトリョーシカ表現学習では、灰色の縦棒の全次元のベクトルだけでなく、黄色の縦棒の半分の次元数のベクトル、青色の縦棒の¼の次元数のベクトル、オレンジ色の⅛の次元数のベクトルに対しても損失を計算し、モデルのパラメータを更新します。これにより、学習後のモデルは、マトリョーシカ表現学習のコンセプトである「ベクトルの前半に大雑把な情報、後半に詳細な情報が含まれているようなベクトルを作る」ようになります。
(引用:Matryoshka Representation Learning)
従来の埋め込みモデルとの性能の違い
OpenAIの発表「新しい埋め込みモデルと API の更新」によると、「text-embedding-3-small」と「text-embedding-3-large」は従来の「text-embedding-ada-002」よりも精度が高いと報告されています。
例えば、表5のように、MIRACLE(多言語での情報検索タスク)とMTEB(埋め込みモデル評価用の8つのタスク)における平均スコアは、どれも従来の「text-embedding-ada-002」を上回るスコアとなりました。特にMIRACLEでは平均スコアが大幅に上昇しました。
| 評価ベンチマーク | text-embedding-ada-002 | text-embedding-3-small | text-embedding-3-large |
|---|---|---|---|
| MIRACLE | 31.4 | 44.0 | 54.9 |
| MTEB | 61.0 | 62.3 | 64.6 |
(出典:「新しい埋め込みモデルと API の更新」)
また、表6のように、「text-embedding-3-small」と「text-embedding-3-large」から出力されるベクトルの次元数を小さくした場合においても、従来の「text-embedding-ada-002」より精度が高いと報告されています。
| text-embedding-ada-002 | text-embedding-3-small | text-embedding-3-large | ||||
|---|---|---|---|---|---|---|
| 出力される ベクトルの次元数 |
1536 | 512 | 1536 (デフォルト) |
256 | 1024 | 3072 (デフォルト) |
| 平均スコア | 61.0 | 61.6 | 62.3 | 62.0 | 64.1 | 64.6 |
(出典:「新しい埋め込みモデルと API の更新」)
「text-embedding-3-small」は、ベクトルの次元数をデフォルトの⅓に削減しても従来の「text-embedding-ada-002」より精度が高いです。また、「text-embedding-3-large」は、ベクトルの次元数をデフォルトの1/10に削減しても従来の「text-embedding-ada-002」より精度が高いです。
世の中にある埋め込みモデル
たまちゃんではAzure OpenAI Serviceで利用可能なOpenAIの埋め込みモデルを採用していますが、世の中にはOpenAI以外にも、様々な企業や団体が埋め込みモデルを公開しています。Azure OpenAI Serviceを採用していないケースでは、表7に記載したモデルが活用できると考えられます。
| # | モデル | 提供企業・団体名 | 備考 |
|---|---|---|---|
| 1 | text-embedding-ada-002,text-embedding-3-small, text-embedding-3-large |
OpenAI |
|
| 2 | Amazon Titan Text Embeddings V2 | Amazon | Amazon Bedrockから利用可能 |
| 3 | textembedding-gecko | Google Cloudで提供されているMLサービスのVertex AIにおいて利用可能 | |
| 4 | embed-multilingual | Cohere | Amazon Bedrockからも利用可能 |
| 5 | voyage-3 | Voyage AI |
|
| 6 | GLuCoSE v2, RoSEtta | PKSHA Technology | 日本語特化の埋め込みモデル |
検証結果
たまちゃんのベクトル検索で使用している埋め込みモデルを変更した場合の精度は、表8のようになりました。
| # | モデル | 出力される ベクトルの次元数 | 評価データに対する正解率 (評価データ:45件) |
|---|---|---|---|
| (現行)1 | text-embedding-ada-002 | 1536 | 71% |
| 2 | text-embedding-3-small | 1536 | 67% |
| 3 | text-embedding-3-large | 3072 | 71% |
まず、「text-embedding-3-small」に変更した場合は、現行のモデルよりも精度が下がりました。これは正解を含むドキュメントがベクトル検索で上手くヒットしなくなった結果、回答できなかったケースが増えたためです。実際、これまで3位や4位で検索にヒットしていたドキュメントが、10位以下になってしまう場合があることも確認できました。
次に、「text-embedding-3-large」に変更した場合は、現行のモデルと同じ精度になりました。精度向上しなかった要因としては、ベクトル検索の後に、より強力で精度向上に寄与しやすい検索手法(ハイブリッド検索とセマンティックランカー)を適用していることで、埋め込みモデルによるベクトル検索の差が現れづらかったことが考えられます。
また、「text-embedding-3-large」では、生成されるベクトルの次元数が増えるため、Azure AI Searchに登録されるベクトルデータのサイズが現行の約2倍になることも確認しました。 なお、「text-embedding-3-large」は、現行の「text-embedding-ada-002」よりも大きいモデルですが、検索速度の低下は感じられませんでした。
以上の検証結果から精度の違いはほとんどありませんでしたが、Azure側で移行を推奨されている点も踏まえ、「text-embedding-3-large」への切り替えを決定しました。
おわりに
今回の記事で紹介した2つの施策の結果を表9にまとめました。
| 施策 | 課題の種類 | 評価データに対する正解率 | 回答精度の向上度合 | 導入コスト | 補足 |
|---|---|---|---|---|---|
| (実施例) | ー | 53% | ー | ー | 評価データに対する正解率が約50%になるように評価データを準備 |
| 改善事例 vol.1 | ー | 63% (+10) |
ー | ー | 適用した施策
|
| 改善事例 vol.2 | ー | 83% (+20) |
ー | ー | 適用した施策
|
| 評価データの見直し | ー | 60% (-23) |
ー | ー | 精度を計測しやすくするため、回答できないデータを評価データに追加。そのため、回答精度が改善事例vol.2の83%から60%に下がっている |
| チャンクサイズの調整 | 回答生成の課題 | 69% (+9) |
中 | 中 |
|
| 埋め込みモデルの最新化 | 検索の課題 | 71% (+2) |
低 | 中 |
|
今回の記事では、「チャンクサイズの調整」と「埋め込みモデルの最新化」という2つの施策についてご紹介しました。
「チャンクサイズの調整」では、チャンクサイズを3000文字、オーバーラップを900文字に設定することで、評価データに対する正解率を9ポイント向上させることができました。これにより、従来よりも詳細かつ適切な情報を提供できるようになった事例も見られました。
「埋め込みモデルの最新化」では、現行の「text-embedding-ada-002」と比較すると正解率はほぼ変わりませんでしたが、Azureが推奨している新しい「text-embedding-3-large」への移行を決定しました。
改善事例vol.2の時点から評価データを見直したことにより、ベースラインとなる正解率は変動していますが 、今回ご紹介した施策によって着実に改善を進めています。以降の取り組みについては、本コラムで順次紹介する予定です。
最後までお読みいただき、誠にありがとうございました。
本記事に記載されているロゴ、システム名称、企業名称、製品名称は各社の登録商標または商標です。
執筆者紹介



連載コラム:エクサの生成AIチャレンジ日記
本コラムでは、エクサ社内における生成AIの活用に向けた技術的な取り組みと、実際の業務適用事例をご紹介いたします。生成AIによる業務効率化や新たな価値創造のヒントとなれば幸いです。
関連コラム

関連ソリューション






関連事例


お問い合わせ
CONTACT
Webからのお問い合わせ
エクサの最新情報と
セミナー案内を
お届けします
