


回答が見つかりませんでしたって言われちゃうことが多いんだよな...。

たまちゃん、もっと的確に答えられるように、なんとか精度を上げたいんですよね!
どれくらいちゃんと答えられてるのか分からないと、改善も難しそう...。

ちゃんと測ってみることから始めようと思ってるんです。
はじめに
コラム『社内情報に特化したAIアシスタント「たまちゃん」』では、たまちゃんの仕組みや、RAG(検索拡張生成)という技術、そしてハルシネーション対策などについてご紹介しました。
たまちゃんは、社内情報を元に社員からの問い合わせに答えてくれるAIアシスタントとして誕生しました。しかし、仕組み自体はできあがったものの、実際に使ってみると、まだうまく質問に答えられない場面も少なくありませんでした。
「このままでは、せっかく作ったたまちゃんも使ってもらえないかもしれない...」
「なんとかして、もっと的確に答えられるように、たまちゃんの回答精度を上げたい!」
しかし、やみくもに改善策を試しても、それが本当に効果があったのかどうか分かりません。
精度を上げるためには、まず「現在のたまちゃんの精度はどれくらいなのか?」を客観的に測るための仕組み作りが不可欠でした。
そこで今回は、私たちが「たまちゃん」の回答精度をどのように測定し、改善につなげているのか、その「精度計測」の仕組みについて、少し詳しくご紹介したいと思います。
AIアシスタントの回答精度、どうやって測る?評価の難しさ
AIアシスタントの回答精度を測るのは、実は簡単なことではありません。AIアシスタントとの会話は自然言語で行われるため、数学の問題のように「正解は一つ」と決まっているわけではなく、同じことを説明した文章でも何通りもの言い方があります。
自然言語処理タスクの中でも、機械翻訳では参照テキスト(正解文やお手本となる文)と生成テキストとの間で、どれだけ単語やフレーズが一致しているかを測る評価指標(例: BLEU、ROUGE)が広く使われています。これらの指標は、語彙や表現がある程度定まっているタスクでは有効です。
しかし、AIアシスタントの質問応答においては、これらの単語一致率に基づく指標だけでは限界があります。先述した通り、一つの質問に対して表現は違えど「正しい」と言える回答が複数存在しうるからです。
例えば、「名刺の作成方法を教えて」という質問を考えてみましょう。
- 回答A: 「社内ポータルサイトにアクセスし、『各種申請』メニューの中にある『名刺発注依頼』フォームに必要事項を記入して申請してください。」
- 回答B: 「イントラネットの申請メニューから『名刺発注依頼』を選択し、手続きします。」
AもBもユーザーの目的を達成する上で有効な回答ですが、使われている単語の重なりは少ないです。そのため、単語の一致率を測る方法では、どちらか一方を正解としても、もう一方は「不正解」に近いと評価されてしまう可能性があります。
このように、AIアシスタントの応答を適切に評価するには、単語だけでなく、回答が意味的にユーザーの意図を満たしているかを捉える必要があります。そこで注目されているのが、「LLM-as-a-Judge」という評価方法です。
「AIがAIを評価する」LLM-as-a-Judgeという考え方
LLM-as-a-Judgeとは、大規模言語モデル(以降、LLMと表記)の出力品質を評価するために、別の高性能なLLMを「審査員(Judge)」として利用する手法のことです。人間による評価は時間やコストがかかり、評価者によって基準がぶれる可能性があるため、その代替または補完として注目されています。
LLM-as-a-Judgeには、人間が評価するのに近いレベルで文脈や意図を汲み取った評価を自動で行えるというメリットがあります。研究によっては、AIによる評価と人間による評価の一致率が、人間同士の一致率を超えるという報告もあるほどです(Zheng et al. 2023)
一方、AIによる評価のデメリットとしてLLMが持つ「バイアス」が評価結果に影響を与える可能性があることが挙げられます。LLMが持つバイアスの例として、特定の言い回しを好む、長文を高く評価する、最初や最後に提示されたものを高く評価するといった傾向が報告されています。
LLM-as-a-Judgeは、LLMの評価を効率化・自動化するための強力な手法です。人間による評価を完全に置き換えるものではありませんが、そのスケーラビリティと速度から、LLMの開発サイクルにおいて重要な役割を果たしています。バイアスを理解し、適切に利用することが求められます。
LLM-as-a-Judgeを使ったRAGの評価
LLM-as-a-Judgeの手法は、RAGの評価においても有効なアプローチです。RAGは、ユーザーの質問に対し、まず関連情報を検索し、その検索結果に基づいてLLMが回答を生成するという、検索と回答生成の二段階のプロセスを経ています。そのため、RAGの評価では、単に最終的な回答の質を見るだけでなく、以下の二つの観点から評価を行うことが重要です。
- 検索精度: 質問に対して、回答生成に必要な情報を含む関連ドキュメントを適切に検索できているか。
- 生成精度: 検索されたドキュメントの内容に基づいて、質問の意図に沿った正確で自然な回答を生成できているか。
LLM-as-a-Judgeを用いることで、これらの観点に基づいた評価を自動化し、効率的に行うことが可能になります。例えば、「検索は成功したが生成で失敗した」あるいは「そもそも検索が失敗していた」といった、RAGのボトルネックがどこにあるのかを特定するのに役立ちます。
LLM-as-a-JudgeをRAGの評価に適用する場合のフローは以下のようになります(図1)。
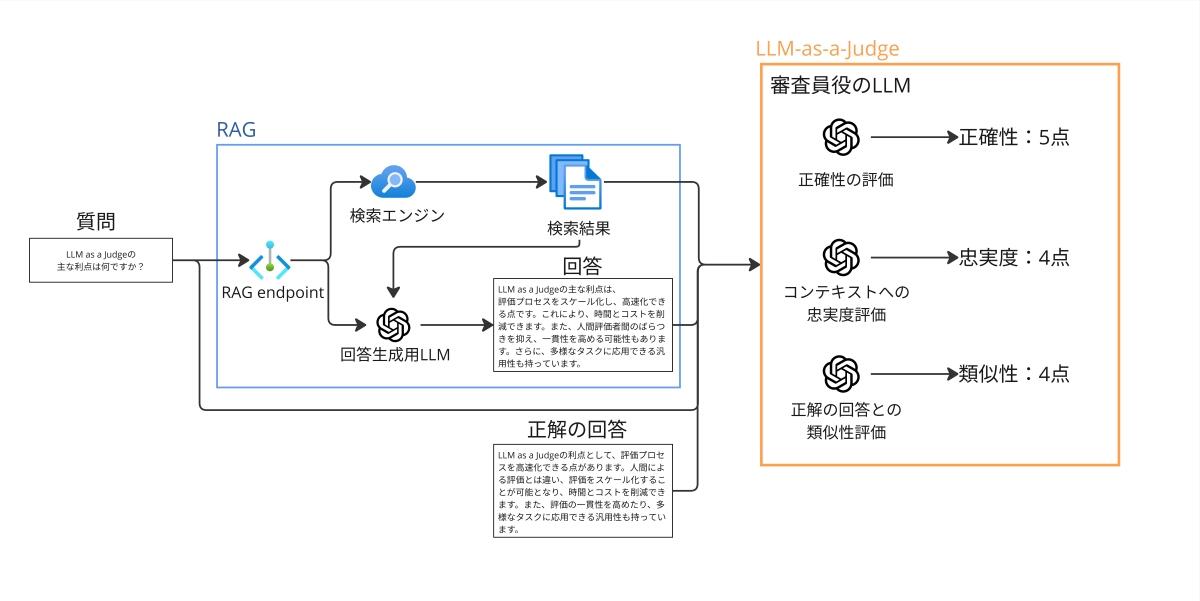
RAGの評価ではまず、 評価用の質問をRAGに入力し、関連ドキュメント(コンテキスト)の検索と回答生成を行います。評価時には、生成された「回答」、検索された「コンテキスト」、元の「質問」、そして場合によっては事前に用意された「正解の回答」を、審査員役のLLMに入力します。
審査員役のLLMは、与えられた情報に基づき、定義された評価基準(例えば、回答の正確性、コンテキストへの忠実度、正解の回答との類似性など)に従ってスコアを付けます。この際、評価の観点や基準をプロンプトで明確に指示することが重要です。
評価データの準備
実際にLLM-as-a-Judgeの仕組みを用いてRAGの精度を測るためには、評価データを準備する必要があります。評価データとは、質問文と、それに対する正解の回答文のペアを複数用意したものです。実は、この評価データを準備する際にも様々な方法があります。評価データの作成方法を表1にまとめました。
| # | 方法 | 説明 | メリット | デメリット |
|---|---|---|---|---|
| 1 | 手動でデータ作成 | 人間が手動で質問文と回答文のペアを作成し、評価データとする。 |
|
|
| 2 | 既存のFAQを使用する | 既存のFAQリストから質問と回答文を取得し、評価データとする。 |
|
|
| 3 | AIアシスタントの利用ログを活用する | 実際のユーザーからの質問と、AIの回答ログ(または人間がフォローした正解)をデータとする。 |
|
|
| 4 | LLMを使って評価データを自動生成する | 対象となるドキュメントをLLMに読み込ませ、質問と回答のペアを自動生成する。 |
|
|
たまちゃんの評価データは、表1の「#3. AIアシスタントの利用ログを活用する」方法と、「#4.LLMを使って評価データを自動生成する」方法を組み合わせて作成しています。
具体的には、まず#3のアプローチで、実際の利用ログが蓄積されているSlackチャンネルからデータを収集しました。この際、たまちゃんがうまく質問に答えられたケースと、答えられなかったケースが、おおよそ半々ぐらいになるように意識して質問と回答(あるいは人間がフォローした正解)のペアを集めました。これにより、成功パターンだけでなく、改善が必要なパターンも評価できるようにしています。
さらに、#4のアプローチでは、特にたまちゃんが苦手としていた社内規定に関する文書をLLMに読み込ませ、それに関する質問と回答のペアを生成しました。これにより、特定の弱点分野における精度を重点的に評価・改善するためのデータも確保しました。
このように複数の方法を組み合わせることで、より網羅的で、かつ実際の利用状況や課題に即した評価データセットの構築を目指しました。
評価の実装
ここからは、用意した評価データを使って、実際にどのように評価を行ったのかについてご紹介します。
様々な評価ツールや手法を検討した結果、私たちはRAGの評価によく用いられているオープンソースのツールであるRAGAS (Retrieval Augmented Generation Assessment) を採用することにしました。
RAGASは、LLMを用いたアプリケーション、特にRAGの評価に特化したツールを提供するPythonライブラリです。
このライブラリの便利な点は、LLM-as-a-Judgeの手法を用いた評価だけでなく、BLEUやROUGEといった従来の自然言語処理で使われてきた評価指標も利用できることです。さらに、評価対象のRAGが参照するドキュメント群から、評価用のテストデータを自動生成する機能も備えています。
RAGASで利用できる評価指標の一部を抜粋して表2にまとめました。たまちゃんの評価は回答生成品質と検索品質の両面から評価を実施できるように、これらの評価指標を組み合わせて評価を行っています。
| 評価項目 | 概要 | 目的 | 評価対象 | 評価時の入力 |
|---|---|---|---|---|
| 忠実性 (Faithfulness) |
生成した回答が検索した文書に基づいているか(検索した文書に忠実であるか)を測定 | ハルシネーションを抑制し、応答がコンテキストに根拠づけられているかを確認 | 回答生成品質 |
|
| 回答関連性 (Response Relevancy) |
生成した回答が質問にどれだけ関連しているかを評価する | 生成した回答が質問の意図に合致し、冗長性や不足がないかを確認 | 回答生成品質 |
|
| 事実正確性 (Factual Correctness) |
生成した回答を、正解の回答と比較し、その事実としての正確性を評価する指標 | 生成した回答の事実としての正しさを評価 | 回答生成品質 |
|
| 意味的類似性 (Semantic Similarity) |
生成した回答と正解の回答との意味的類似性を評価する | 生成した回答と正解の回答が意味的にどれだけ近いかを評価 | 回答生成品質 |
|
| 文脈適合率 (Context Precision) |
検索した文書中の、質問に関連する文章の割合を測定 | 検索結果のノイズ(無関係な情報)の少なさを評価 | 検索品質 |
|
| 文脈再現率 (Context Recall) |
質問に答えるために必要な全ての情報(正解の回答に含まれる情報)が、検索した文書内に含まれているかどうかを測定 | 検索結果が必要な情報を漏れなく含んでいるかを評価 | 検索品質 |
|
これまでに用意してきた評価データと、RAGASの評価指標を使って実際にたまちゃんの評価を行う流れを図2に示しました。
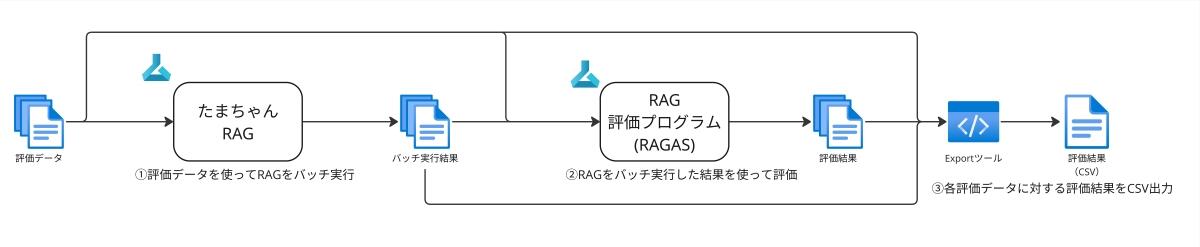
たまちゃんの評価システムでは、まず初めに評価データ(たまちゃんでは50件の質問と回答の組)を使ってRAGをバッチ実行し、その結果を使ってRAGの評価プログラムを実行します。RAGの評価プログラムでは、審査員役のLLMとして低コストなGPT-4o-miniを使用しています。最後に、RAGの実行結果、評価結果をまとめてCSVにエクスポートすることで、精度の確認を行います。
評価結果をエクスポートしたCSVには、評価データ1件ずつに対して、RAGの検索結果と回答、各評価項目に対する評価結果を数値で出力しています。そのため、回答できなかった場合には検索で正解の文書を見つけられなかったのか、検索できているにも関わらず回答生成がうまくいかなかったのか、など詳細な情報を確認することができます。この情報を元に、たまちゃんの精度改善のためにはどのような施策を実施するべきなのかを検討し、精度改善に取り組んでいます。
おわりに
本記事では、AIアシスタント「たまちゃん」の精度評価について、LLM-as-a-Judgeという評価方法、評価データの作成、そしてRAGASを使った具体的な評価実装についてご紹介しました。
ここまでで、ようやくたまちゃんの精度改善を行うための基盤が出来上がりました。ここから、いよいよ、たまちゃんの精度改善への取り組みがスタートします。精度改善の具体的な取り組みについては、次回のコラムでご紹介いたします。
最後までお読みいただき、誠にありがとうございました。
本記事に記載されているロゴ、システム名称、 企業名称、製品名称は各社の登録商標または商標です。
執筆者紹介


連載コラム:エクサの生成AIチャレンジ日記
本コラムでは、エクサ社内における生成AIの活用に向けた技術的な取り組みと、実際の業務適用事例をご紹介いたします。生成AIによる業務効率化や新たな価値創造のヒントとなれば幸いです。
関連コラム

関連ソリューション






関連事例


お問い合わせ
CONTACT
Webからのお問い合わせ
エクサの最新情報と
セミナー案内を
お届けします
